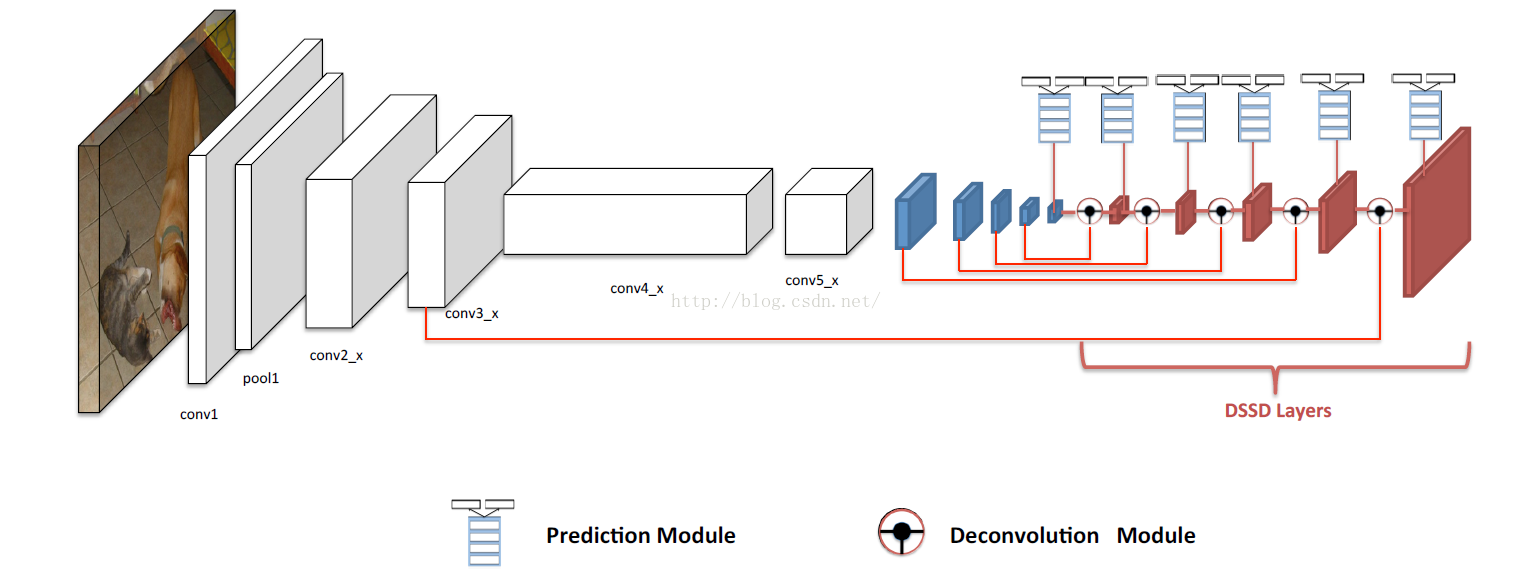
这篇文章将额外的上下文信息引入到目标检测中,首先将ResNet-101和SSD组合,,然后利用反卷积层扩增这个组合的网络,为目标检测引入大尺度的上下文信息,提高准确率,特别是对小目标的检测。Deconvolutional single shot detector,因此简称DSSD。实验结果比R-FCN要好。
YOLOv3:An Incremental Improvement
这篇文章发表于2018年,比YOLOv2网络更大,但是更精确。在320x320的分辨率下,YOLOv3处理一幅图需要22ms,mAP为28.2,与SSD一样精确但是快3倍。主要的创新点有3个:类别预测上不再使用softmax而是使用独立的logistic回归,能实现多标签预测;类似于FPN,实现多尺度预测,将不同层的特征做了融合;提出更好的基础网络,加入残差块。
YOLO9000:Better, Faster, Stronger
这篇文章发表在2016年,提出了YOLO的第二个版本。YOLOv2在67FPS的检测速度下,可以在VOC2007上达到76.8的mAP。在40FPS的速度下,有78.6的mAP,比使用ResNet的Faster R-CNN和SSD更好。YOLO9000可以检测超过9000种目标。
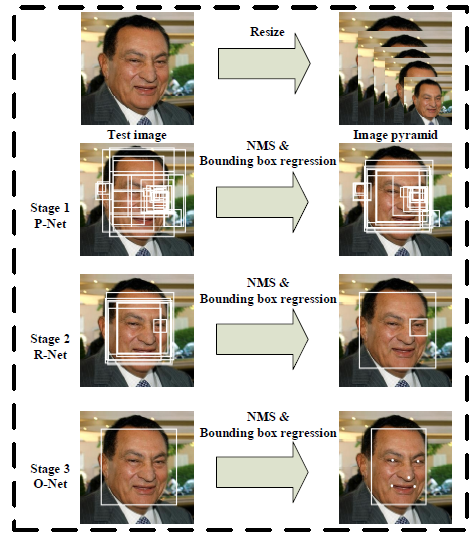
Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
提出一种深度级联的多任务框架,利用检测和对齐的固有相关性去增强它们的性能。实际中,利用有三阶段精细设计的深度卷机网络的级联结构,由粗到精地检测和对齐人脸。
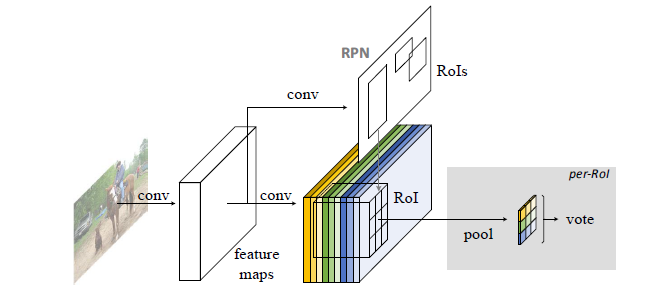
R-FCN:Object Detection via Region-based Fully Convolutional Networks
这篇文章发表在
CVPR2016上,提出位置敏感分数图(position-sensitive score map)去权衡图像分类中的平移不变性和目标检测中的平移变换性这种两难的境地。
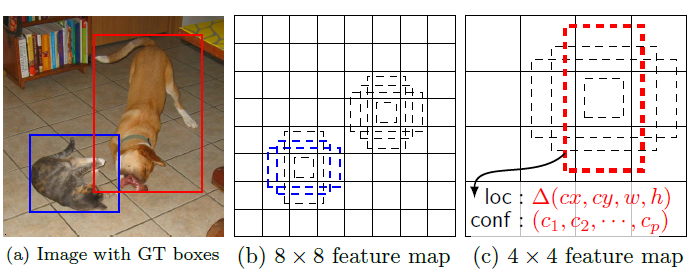
SSD:Single Shot MultiBox Detector
这篇文章发表在
ECCV2016上,在既保证速度,又要保证精度的情况下,提出了SSD。使用single deep neural network,便于训练与优化,同时提高检测速度。SSD将bounding box的输出空间离散化为一组默认框,这些默认框在feature map每个位置有不同的高宽比和尺度。在预测时,网络对每一个默认框中存在的目标生成类别分数,并且调整边界框以更好地匹配目标形状。除此之外,网络对不同分辨率的feature map进行组合,以处理各种尺寸的目标。
YOLO
过去的目标检测都是用分类器去实现检测,本文构造的检测器,将目标检测作为一种回归空间分离的边界框和相关类概率的问题。一次预测中,一个神经网络(
single network)直接从整幅图像中预测出边界框和类别概率,是一种端到端的实现。
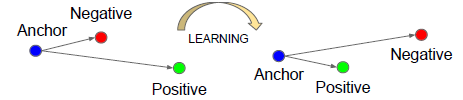
FaceNet:A Unified Embedding for Face Recognition and Clustering
这篇文章是
CVPR2015上的文章,提出了FaceNet直接学习人脸图像到一个紧凑的欧氏空间的映射,空间距离直接对应于面部相似度的测量。主要的创新点就是提出使用triplet loss,并且得到的是128维的特征。在LFW数据集上达到了99.63%的准确率,在YouTube Faces DB达到了95.12%的准确率。
DeepID:Deep Learning Face Representation from Predicting 10,000 Classes
这篇文章提出使用深度学习去学习到一个高级的特征表达集合
DeepID用于人脸验证。DeepID特征是从深度卷积神经网络的最后一个隐含层神经元激励提取到的。并且这些特征是从人脸的不同区域中提取的,用来形成一个互补的过完备的人脸特征表达。

Rapid Object Detection using a Boosted Cascade of Simple Features
这篇文章是人脸检测的经典,提出一种基于机器学习的视觉目标检测方法,主要有三点贡献:第一,引入“积分图”概念,可以被检测器用来快速计算特征。第二,学习算法基于
AdaBoost,可以从很大的集合中筛选出少量的关键视觉特征并形成更加高效的分类器。第三,以“级联”形式逐渐合并复杂分类器的方法,该方法使得图像的背景区域被很快丢弃,从而将更多的计算放在可能是目标的区域上。
