这篇文章是人脸检测的经典,提出一种基于机器学习的视觉目标检测方法,主要有三点贡献:第一,引入“积分图”概念,可以被检测器用来快速计算特征。第二,学习算法基于
AdaBoost,可以从很大的集合中筛选出少量的关键视觉特征并形成更加高效的分类器。第三,以“级联”形式逐渐合并复杂分类器的方法,该方法使得图像的背景区域被很快丢弃,从而将更多的计算放在可能是目标的区域上。
Introduction
本文建立了一个正面的人脸检测系统,常规700 MHz英特尔奔腾III,人脸检测速度达到了每秒15帧。其他的人脸检测系统提高帧率是利用视频序列中的图像差异,或者彩色图像中像素的颜色,本文的系统仅仅利用灰度图像信息就实现了高帧率。
三点贡献:
- 提出积分图,快速地计算特征。在一幅图像中,每个像素使用很少的一些操作,就可以计算得到积分图。任何一个
Haar-like特征可以在任何尺度或位置上被计算出来,且是在固定时间内。 - 提出了一种通过
AdaBoost选择少量重要特征的方法。在任何的图像子窗口中,Haar-like特征数量是非常大的,通常远大于像素数量。为了获得快速的分类,学习算法必须排除掉获取的特征中的大部分,关注少量关键特征。通过对AdaBoost程序简单修改:约束弱学习器,使得返回的弱分类器只依赖于一个简单特征。因此,boosting过程的每一个阶段,选择一个新的弱分类器,这些阶段可以被视为特征选择过程。 - 提出了一种以级联的方式逐渐合并更加复杂的分类器的方法,通过关注图像中那些更有希望的区域,这大大地提高了检测速度。
这些没有被最初的分类器排除的子窗口,由接下来的一系列分类器处理,每个分类器都比其前一个更复杂。如果一个子窗口被任何分类器拒绝了,则它就不再被进一步处理。
Features
使用三种特征:
- 双矩形特征:其值定义为两个矩形区域里像素和的差。这两个区域有着相同的尺寸和形状,并且水平或垂直连接。如图
A和B。 - 三矩形特征:其值定义为两个外矩形像素和减去中间矩形像素和。如图
C。 - 四矩形特征:其值定义为对角线上的矩形对的差。如图
D。
Integral Image
积分图:某个位置上的左边和上边的像素点的和。位置(x,y)上的积分图像包含点(x,y)上边和左边的像素和。如下式,ii(i,y)是(x,y)位置的积分图,i(x,y)是原始图像的像素值。
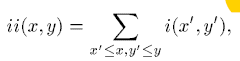
使用下面的两个式子迭代,其中s是累计行和,s(x,-1)=0,ii(-1,y)=0:

使用积分图像可以把任意一个矩形用四个数组引用计算,例如下图中的D,位置1上的积分图的值是矩形A的像素和,位置2上积分图的值是A+B,位置3则是A+C,位置4是A+B+C+D,矩形D的和可以计算为:4+1-(2+3):

由上图也可以看出,两个矩形像素和之间的差可以通过8个数组引用来计算。因为双矩形特征涉及到两个相邻矩形的和,所以仅用6个数组引用就可以计算出结果。同理三矩形特征用8个,四矩形特征用9个。
Learning Classification Functions
本文中,AdaBoost的一个变体被用于选择一个小集合的特征并且训练分类器。原始的AdaBoost学习算法被用于加强简单(弱)分类器的性能。每一个图像子窗口相关的特征超过180000,远超过像素的数量。而这些特征中只有一小部分可以被组合形成一个有效的分类器。所以主要的挑战是找到这小部分的特征。
弱学习器用来选择能将正负样本最好的分离的单个特征。对于每一个特征,弱学习器确定最优的阈值分类函数,以使被误分类的样本数量最少。弱分类器hj(x)包括:特征fj,阈值θj,和一个正负校验pj,表示不等号的方向,x是24×24的图像子窗口。
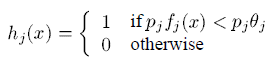
学习算法如下:

Learning Result

对于人脸检测的任务,由AdaBoost选择的最初的矩形特征是有意义的且容易理解。选定的第一个特征的重点是眼睛区域往往比鼻子和脸颊区域更黑。此特征相对于检测子窗口较大,并且某种程度上不受面部大小和位置的影响。第二个特征选择依赖于眼睛的所在位置比鼻梁更暗
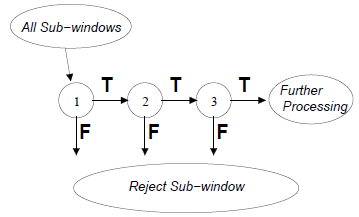
The Attentional Cascade
本章提出的构建级联分类器的算法,它能增加检测性能从而从根本上减少计算时间。主要观点是构建一种优化分类器,其规模越小就越高效。这种分类器在检测几乎所有的正样本时剔除许多负子窗口(即,优化分类器阈值可以调整使得false negative率接近零)。在调用较复杂的分类器之前,我们使用相对简单的分类器来剔除大多数子窗口,以实现低false negative率。
在检测过程中,整体形式是一个退化决策树,称之为“级联”(cascade)。从第一个分类得到的有效结果能触发第二个分类器,它已经调整达到非常高的检测率。再得到一个有效结果使得第二个分类器触发第三个分类器,以此类推。在任何一个点的错误结果都导致子窗口立刻被剔除。
级联阶段的构成首先是利用AdaBoost训练分类器,然后调整阈值使得false negative最大限度地减少。注意,默认AdaBoost的阈值旨在训练数据中产生低错误率。一般而言,一个较低的阈值会产生更高的检测速率和更高的false positive率。
一个双特征强分类器通过降低阈值,达到最小的false negatives后,可以构成一个优秀的第一阶段分类器。测量一个训练集时,阈值可以进行调整,最后达到100%的人脸检测率和40%的正误视率。
Training a Cascade of Classifiers
在实践中用一个非常简单的框架产生一个有效的高效分类器。级联中的每个阶段降低了false negatives并且减小了检测率。现在的目标旨在最小化false negatives和最大化检测率。调试每个阶段,不断增加特征,直到检测率和false negatives的目标实现(这些比率是通过将探测器在验证集上测试而得的)。同时添加阶段,直到总体目标的false negatives和检测率得到满足为止。
Result
Scanning the Detector
最终的检测器在多个尺度和位置上扫描图像。尺度缩放是缩放检测器自身而不是缩放图像。这个过程有效是因为特征可以在任意尺度下被评估。使用1.25的间隔可以得到良好结果。
检测器也在位置上扫描。后续位置的获得是通过将窗口平移⊿个像素获得的。这个平移过程受检测器的尺度影响:若当前尺度是s,窗口将移动[s⊿],这里[]是指取整操作。⊿的选择不仅影响到检测器的速度还影响到检测精度。我们展示的结果是取了⊿=1.0。通过设定⊿=1.5,我们实现一个有意义的加速,而精度只有微弱降低。
Integration of Multiple Detections
因为最终检测器对于平移和尺度的微小改变是不敏感的,在扫描一幅图像时每个人脸通常会得到多检测结果,一些类型的false positives也是如此。在实际应用中每个人脸返回一个最终检测结果才显得比较有意义。
在这些试验中,用非常简便的模式合并检测结果。首先把一系列检测分割成许多不相交的子集。若两个检测结果的边界区重叠了,那么它们就是相同子集的。每个不相交的集合产生单个最终检测结果。最后的边界区的角落定义为一个集合中所有检测结果的角落平均值
A simple voting scheme to further improve results
运行三个检测器的结果(一个本文描述的38层检测器加上两个类似的检测器),输出投票得票数高的结果。在提高检测率的同时也消除很多false positives率,且随检测器独立性增强而提高。由于它们的误差之间存在关联,所以对于最佳的单一检测器,检测率是有一个适度提高。