这篇论文发表在
NIPS2015上。region proposal计算出现瓶颈,因此引入RPN网络,与检测网络共享整幅图像的的卷积特征,所以region proposal几乎是没有代价的。Faster R-CNN能够达到实时,并且精确度高。
Introduction
R-CNN实际扮演的是分类器,它并不能预测出检测框,只能对检测框进行精修,因此它的准确度主要取决于selective search部分。在之前的方法中proposal是预测时间的瓶颈。
本文使用深度卷积神经网络RPN(Region Proposal Network)计算proposal。在卷积特征的顶部,通过增加一些额外的卷积层,能够在一个规则网格上的每个位置同时回归bounding box并且给出目标得分。RPN是一种全卷积网络,并且可以端到端地训练从而生成proposal。
网络结构如下:
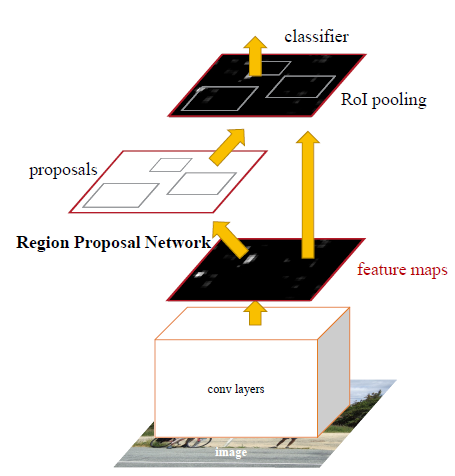
与R-CNN,SPP-Net,Fast R-CNN相比,Faster R-CNN的主要不同在于,不是在原始图像上提取proposal,而是先对原始图像进行卷积得到feature map,然后利用RPN在feature map上提取proposal。
Faster R-CNN
Faster R-CNN由两个模块构成:用于生成region的全卷积网络RPN;Fast R-CNN检测器。RPN模块告诉Fast R-CNN检测器应该“看”哪里。
Region Proposal Networks (RPN)
RPN采用任意尺寸的图像作为输入,然后输出一系列的带有目标得分(是否有目标)的proposal。这一过程使用一个全卷积网络。
- 为生成
region proposal,在最后一个共享的卷积层输出的feature map上使用一个n×n的滑动窗(本文n=3) - 在每一个滑动窗的位置,同时预测多个
region proposal,每个位置最大可能的region proposal个数定义为k,文中是9。reg层输出就为4k,cls层输出为2k个分数,对应于每一个region proposal为目标或非目标的概率。 - 每一个
anchor被放置在滑动窗的中心。默认使用3个尺度和3个高宽比,所以每一个滑动窗位置上有9个anchor。对于一个W×H的卷积feature map而言,共有WHk个ahchor。 - 每一个滑动窗被映射为一个低维特征,其实就是一个
3x3的卷积核,卷积后得到1个数值,256个通道在一个窗口卷积后就是256-d的特征,后面跟随ReLu激活函数。然后经过其他层,最后被输入进两个并行的全连接层:box-regression layer(reg) 和box-classification layer(cls)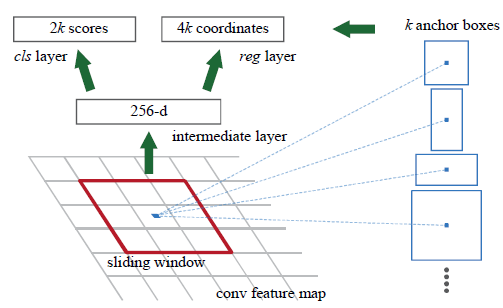
本文的方法具有平移不变性,anchor和相对于anchor的proposal都是平移不变的。也就是说,如果图像中的目标被平移,proposal也应该平移,并且网络依然可以去预测任何位置的proposal。这种平移不变性通过FCN中的方法保证。平移不变性也减少了模型尺寸。
Multi-Scale Anchors as Regression References
多尺度预测一般有两种方法:
- 基于图像/
feature金字塔的:SPPnet,Fast R-CNN - 在
feature map上使用多尺度的滑动窗,如DMP

本文基于anchor金字塔,实现多尺度是根据多尺度和多个高宽比的anchor做分类和回归。这种方法只依赖单尺度的图像和feature map,并且只使用单尺度的filter(feature map上的滑动窗,就是前面说的3x3)。
在SPPnet和Fast R-CNN中,bounding box回归是在从任意大小的RoI池化得到的特征上实现的,回归的权重被所有的region尺寸共享。Faster R-CNN针对不同尺寸,学习k个bounding-box回归器,每一个回归器只负责一个尺度和高宽比,k个回归器之间不共享权重。在后面的Details里会讲到,使用了36个1x1的卷积实现回归的。因为这样的anchor设计,即使特征是固定尺寸或尺度的,也可能预测出不同尺寸的box。
Loss Function
- 为训练
RPN,对每一个anchor分配一个二分类标签:目标或非目标。 - 把一个正标签分配给两种
anchor:与一个ground-truth box有着最高IoU的一个或多个anchor;与任一个ground-truth box的IoU大于0.7的一个anchor。注意一个ground-truth box可能给多个anchor分配了正的标签。(这里我的理解是:每一个ground truth对应的正样本anchor应该与它IoU最高的,但是同时也把那些与它IoU大于0.7的anchor也当做正的,因为涉及到训练深度神经网络需要样本量比较大,因此需要放松条件,不仅是非常符合要求的被选为正样本,也要考虑那些比较符合要求的) - 负标签分配给那些与所有的
ground-truth box的IoU都低于0.3的anchor。那些与真实值IoU为[0,0.2]的anchor不参与训练。
使用multi-task loss:
$$L({p_i},{t_i}) = \frac {1} {N_{cls}} \sum_i L_{cls}(p_i, p_i^*) + \lambda \frac 1 {N_{reg}} \sum_i p_i^* L_{reg}(t_i,t_i^*)$$
带$p_i^*$(值为1或0)是第i个anchor是否为目标的真实值,只有anchor为正样本时,回归的损失才会被算入。
Training RPNs
- 一个
mini-batch使用一张图像,在其中采样256个anchor,正负anchor的比例是1:1,如果正的样本少于负的,则用负样本去填充这个batch,用这256个anchor计算损失 - 使用均值为
0,标准差为为0.01的高斯分布随机初始化所有新添加的层,其他的共享卷积层使用ImageNet上预训练的模型初始化
Sharing Features for RPN and Fast R-CNN
使用交替训练(Alternating Training)实现RPN和Fast R-CNN共享卷积特征,分为4步:
- 使用
ImageNet预训练的模型初始化网络,并且为region proposal任务微调网络。 - 使用
RPN网络生成的proposal,通过Fast R-CNN训练一个单独的检测网络。这个检测网络也是使用ImageNet预训练模型初始化的。到此时,两个网络并没有共享卷积层。 - 使用检测网络初始化
RPN的训练,但是固定共享卷积层,只微调RPN特有的层,实现了两个网络共享卷积层。 - 固定共享卷积,微调
Fast R-CNN特有的层。如此,两个网络共享了相同的卷积层,并且形成了一个统一的网络。
Details
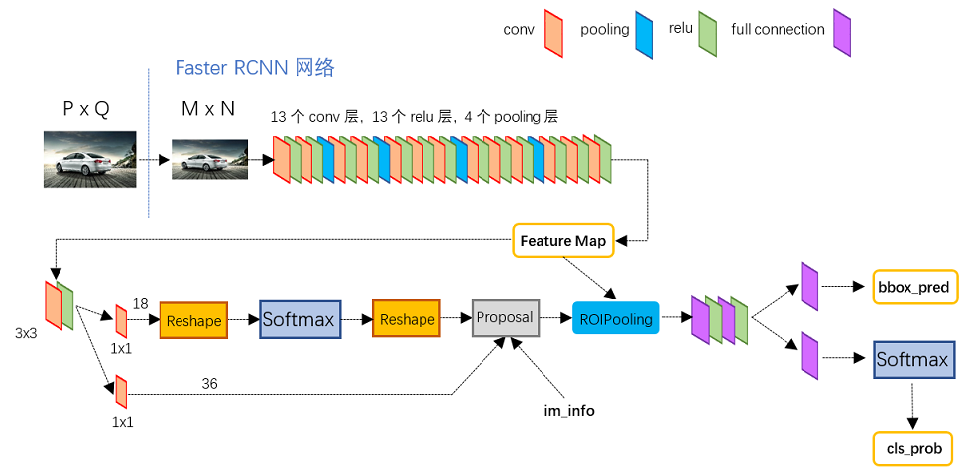
- 输入图像经过
CNN,这里是VGG16,得到feature map feature map首先输入给RPN,做了3x3的卷积,然后分两路:假如前一步3x3卷积后的特征尺寸是是WxHxC,在输入给softmax前使用了18个1x1xC的卷积,得到WxHx18的矩阵,然后分类每个anchor是不是目标;使用36个1x1的卷积,得到WxHx36的矩阵,相当于feature map上每一个位置都有9个anchor,这样得到回归后proposal的位置。RoI Pooling根据RPN的输出,从feature map里提取proposal对应的特征,并且池化成固定尺寸的输出- 最后是全连接层,分类
proposal是哪一类目标;回归bounding box
Faster R-CNN进行了两次bounding box回归,一次是在RPN网络,针对anchor进行回归,目的是使proposal的位置更加接近真实值;一次是在全连接层之后,进行最后的位置回归。
上图中有4个池化层,VGG的特点是每次都是在池化层改变feature map的尺寸。在RPN开始使用的3x3卷积也是保持feature map尺寸不变的,因此原始图像到RPN的feature map被缩放了16倍,所以要想将proposal映射会原图,只需要乘以一个缩放因子。
对于一幅1000x600的图像,经卷积后得到60x40x9 = 20000个anchor(1000/16,600/16)
- 在训练阶段,一幅图中会有约
6000个anchor会超过图像的边界,这部分被去除掉;在测试阶段,对于越过边界的anchor,把它修正到边界上。 - 设置
0.7的阈值进行NMS后,留下约2000的候选框 - 再对剩下的排序它们的得分,提取
top-N个作为最终的proposal。文中经过试验选取前300个效果最好。