这篇文章发表在
ICCV2015上,为了改进R-CNN,SPPnet多阶段训练的缺点,以及SPPnet限制了误差的反向传播的缺点,提出了Fast R-CNN。在训练过程中,使用multi-task loss简化了学习过程并且提高了检测准确率。
Introduction
RCNN的三大缺点:
- 多阶段训练:首先用交叉熵损失微调卷积神经网络;然后线性
SVM拟合卷积特征;最后学习bounding-box回归 - 训练代价高(空间及时间):从每幅图中的每个
region proposal提取的特征需要存储起来 - 测试慢
R-CNN之所以慢,就是因为它独立地warp然后处理每一个目标proposal。流程如下:
提取proposal -> CNN提取feature map -> SVM分类器 -> bbox回归
SPPnet的提出是为了加速R-CNN。但是具有以下缺点:
- 同
R-CNN一样,多阶段,特征需要被写入磁盘 - 不同于
R-CNN的是:微调算法只更新那些跟随在SPP layer后的全连接层。
Fast R-CNN的贡献
- 比
R-CNN更高的检测质量(mAP) - 训练时单阶段的,使用
multi-task loss - 在训练过程中,所有的网络层都可以更新
- 不需要对特征存入磁盘
R-CNN,SPPNet在检测器的训练上都是多阶段的训练,训练起来困难并且消耗时间。SPP-Net限制了训练过程中误差的反向传播,潜在地限制了精确度;目标候选位置需要被精修,过去的精修是在一个单独的学习过程中训练的,Fast-RCNN是对检测器的训练是单阶段的。
Fast R-CNN Training
网络结构上:卷积+池化层 -> RoI pooling layer -> 全连接层。两个并行的层:一个输出类别概率,一个输出四个实值即bounding box。
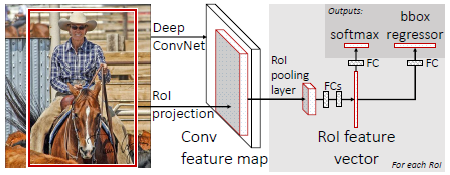
RoI pooling layer
RoI pooling layer是SPPnet中SPP layer的简化版本,相当于金字塔只有一级。SPP-Net中设置了不同样子的网格,比如4x4,2x2,1x1的。
RoI pooling layer的输入是N个feature map和R个感兴趣的区域构成的列表,R>>NN个feature map是由网络的最后一个卷积层提供的,并且每一个都是多维矩阵H×W×C。- 每一个
RoI是一个元组(n,r,c,h,w),指定了feature map的索引n(n为0~N-1)和RoI的左上角位置(r,c)以及高和宽(h,w)。 RoI pooling层输出H'× W'的feature map,通道数和原始的feature map一样(其中,H’ <= H, W’ <=W)。
RoI pooling的具体操作如下:
- 首先将
RoI映射到feature map对应的位置 - 将映射后的区域划分为一定大小的块(
bin),尺寸为h/H' × w/W',h是feature map中ROI的高,H'是要求输出的feature map的高。 - 对每一个块进行
max pooling操作
如下图,输入8×8的feature map,一个RoI(黑色的大框),希望的输出是2×2的。
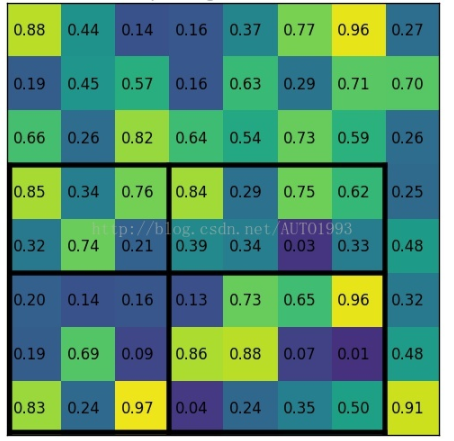
首先找到RoI在feature map中的位置,其大小为7x5;映射后的区域划分为3×2(7/2=3,5/2=2)的块,可能出现如图中,不能整除的情况;最后对每一个块单独进行max pooling,得到要求尺寸的输出。

整个检测框架表示为:
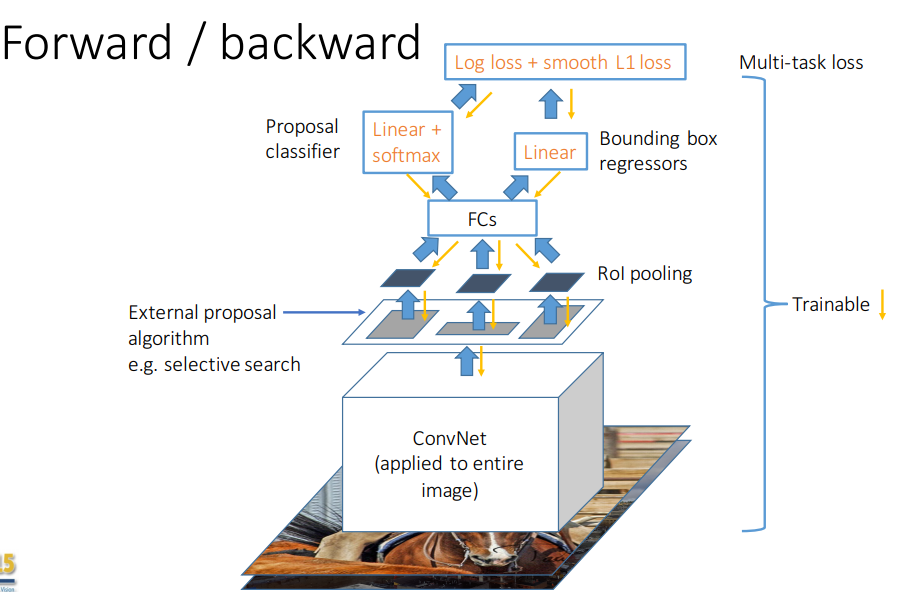
总结一下,Fast R-CNN先用基础网络提取完整图像的feature map,将selective search提取的候选框作为RoI,把feature map和RoI输入给RoI pooling layer,在feature map中找到每一个RoI的位置,根据需要的输出尺寸,把那部分feature map划分网格,对每一个网格应用最大池化,就得到了固定尺寸的输出特征。
Using pretrained networks
使用预训练的网络初始化Fast R-CNN,要经历三个转变:
- 最后一个最大池化层使用
RoI池化层替代。通过设置RoI pooling layer的输出尺寸H'和W'与网络第一个全连接层兼容。 - 网络的最后一个全连接层和
softmax被替代为两个并行的层。 - 网络采取两个数据输入:
batch size为N的输入图像和R个RoIs的列表。
SPP-Net最后是一个3层的softmax分类器用于检测(SPP layer后面是两个全连接层,和一个输出层)。由于卷积特征是离线计算的,所以微调过程不能向SPP layer以下的层反向传播误差。以VGG16为例,前13层固定在初始化的值,只有最后3层会被更新。
在Fast R-CNN中,mini-batch被分层次地采样,首先采样图像,然后采样这些图像的RoIs。来自同一幅图的RoI共享计算和内存,使得训练高效。
Multi-task loss
Fast R-CNN是并行地进行类别的确定和位置的精修的,整体的loss由两部分组成,一部分是分类的损失,另一部分是位置回归的损失,因此定义的损失如下,$k^*$为真实的类别标签,$[k^* \ge 1]$表明只对目标类别计算损失,背景类别的$k^*=0$,提取出的RoI是背景的话,就忽略掉:
$$L(p,k^*,t,t*) = L_{cls}(p,k^*) + \lambda [k^* \ge 1] L_{loc}(t, t^*)$$
$$L_{loc}(t,t^*) = \sum_{i \in {x,y,w,h}} smooth_{L1}(t_i,t^*_i)$$
$$smooth_{L1}(x)=\begin{cases}
0.5x^2, & if~|x|<1 \
|x|-0.5, & otherwise
\end{cases}$$
对于bounding box回归使用Smooth L1 loss是因为,比起R-CNN中使用的L2 loss,Smooth L1 loss对于离群值不敏感。归一化了ground truth的回归目标$t^*$使其具有0均值和单位方差,这样的情况下设置$\lambda = 1$在实验中效果很好。
Detail
- 微调中,
batch size N = 2,R=128,也就是每一幅图采样了64个RoI N张完整图片以50%概率水平翻转R个候选框的构成:与某个真实值IoU在[0.5,1]的候选框被选为RoIs;与真实值IoU在[0.1,0.5]的候选框作为背景, 标记类别为$k^*=0$- 多尺度训练中,和
SPP-Net一样,随机采样一个尺度,每一次采样一幅图