提出一种深度级联的多任务框架,利用检测和对齐的固有相关性去增强它们的性能。实际中,利用有三阶段精细设计的深度卷机网络的级联结构,由粗到精地检测和对齐人脸。
Introduction
人脸识别中视觉的变化,比如遮挡,姿态变化和极端的光照条件,会给人脸检测和对齐带来巨大挑战。AdaBoost和Haar-Like特征训练的级联分类器虽然可以达到比较高的效率,但是大量研究表明这类检测器在人脸有着较大的视觉变化时,检测精度会大大降低。DPM(deformable part models)用于人脸检测也可以达到非常好的性能,然而计算代价太大,并且在训练时可能要求大量的标注。
人脸对齐领域的方法可以大致划分为两类:基于回归的方法和模板匹配方法。过去大部分的人脸检测和对齐方法都忽视了这两种任务之间的固有联系。
另一方面,挖掘难样本对于增强检测器的性能是至关重要的。传统的方法都是离线模式去挖掘,对于人脸检测任务来说,需要一种在线的难阳本挖掘方法,这样可以自动适应当前的训练状态。
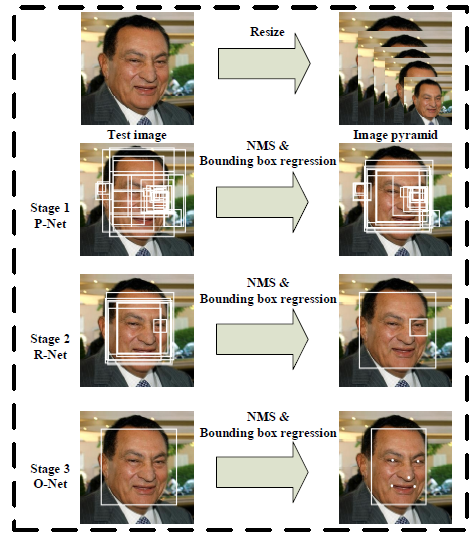
本文中,通过多任务学习使用统一的级联CNNs集成这两种任务。提出的CNNs包含三个阶段:第一阶段,使用浅层的CNN(fast Proposal Network (P-Net))生成候选窗口;第二阶段,通过更加复杂的CNN(Refinement Network (R-Net))去精炼窗口,拒绝掉大量的非人脸的窗口;第三阶段,使用更加强大的CNN(Output Network (O-Net))去再次精修结果并输出5个landmark位置。
贡献:
- 提出一种级联的
CNNs框架做人脸检测和对齐,设计了一种轻量的CNNs结构用于实时性能。 - 提出一种在线难样本挖掘(
online hard sample mining)方法去提高性能。
Approach
Overall Framework
首先将给定图像缩放到不同的尺度建立图像金字塔,这将是后面三阶段级联框架的输入。
第一阶段:采用全卷积神经网络,即
P-Net,去获得候选窗体和bounding box回归向量。同时,候选窗体根据估计的bounding box向量进行校准。然后,利用NMS方法合并高度重叠的候选框。第二阶段:所有的候选框被输入
R-Net,进一步拒绝掉大量的错误候选框,同样使用bounding box回归校正候选框,并实施NMS。第三阶段:和第二阶段相似,但是目的是利用更多的监督去判断人脸区域,并输出
5个landmark位置。
CNN Architectures
多个CNN被用于人脸检测,但其性能可能受到以下情况的限制:
- 卷积层中的卷积核缺乏多样性,限制他们的识别能力;
- 对比多类识别检测和分类任务,人脸检测是一个二分类问题,因此每一层需要的卷积核较少。所以本文减少卷积核数量,并将
5*5的卷积核大小改为3*3的,以此在增加深度来提高性能的同时减少计算。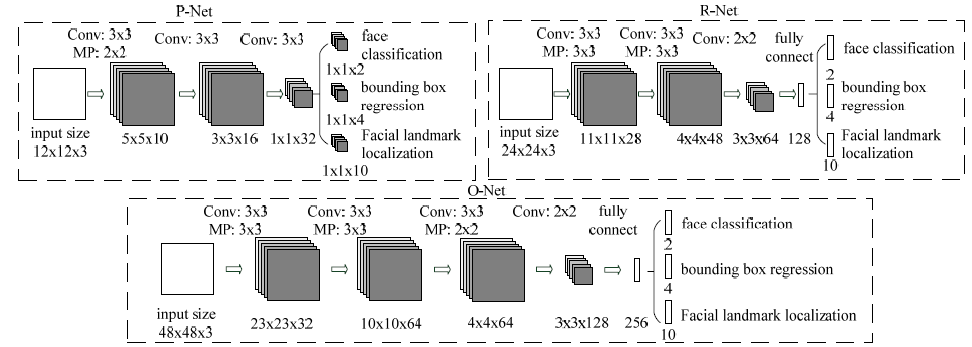
Training
本算法从三个方面对CNN检测器进行训练:人脸分类、bounding box回归、landmark定位(关键点定位)。
人脸分类: 二分类问题,使用交叉熵损失函数:
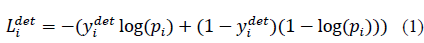
bounding box 回归: 回归问题,使用欧氏距离计算的损失函数:
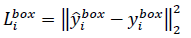
landmark 定位: 回归问题,使用欧氏距离计算损失函数:
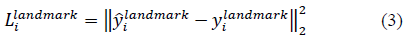
在每个CNN中实现的是不同的任务,所以在学习过程中有几种类型的训练图像:人脸,非人脸,部分对齐的人脸。在这种场合下,上面的式子不能使用,比如,对于背景区域的样本,只需要计算检测损失,其他两种损失设置为0,所以使用一些系数,总体的学习目标表示为:

Online Hard sample mining: 每一个mini-batch中,对从所有的样本前向运算得到的损失排序,选择前70%作为难样本。在反向传播中,只计算来自于这些难样本的梯度。这意味着在训练中忽视掉那些对增强检测器性能帮助甚小的简单样本。
Experiments
在训练中有四种数据:
- 负样本:与任何
ground truth faces的IoU低于0.3的。 - 正样本:与一个
ground truth face的IoU高于0.65的。 Part faces:与一个ground truth face的IoU在0.4~0.65之间的。Landmark faces:标定了5个landmark的。
负样本和正样本用于人脸分类,正样本和part faces用于bounding box回归,landmark faces用于landmark定位。上面的样本比例:3:1:1:2。
数据的收集方法如下:
P-Net:随机地从WIDER FACE数据集中裁切一些图像块,收集正样本,负样本,part人脸。从CelebA数据库裁切人脸作为landmark人脸。R-Net:使用框架的第一阶段在WIDER FACE中检测人脸,收集正样本,负样本和part人脸,同时从CelebA中检测landmark人脸。O-Net:与R-Net相似的方法收集数据。但是是使用前两个阶段去检测人脸和收集数据。