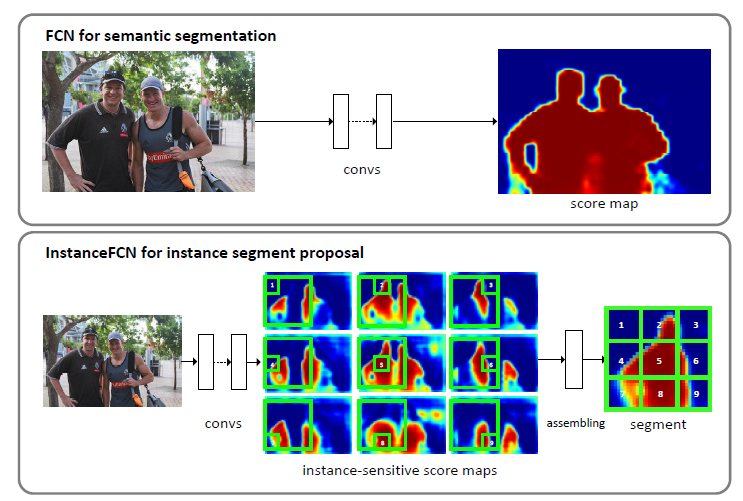
这篇文章发表于2016年,提出了一种全卷积网络,可以计算一组实例敏感的分数图,每一个分数图都是实例中一个相对位置上每个像素分类的结果。之后实例敏感的分数图经过一个简单的组合模块,输出每一个位置的候选实例。
Introduction
FCN并不能直接得到实例分割的结果。因此这篇文章提出了端对端的全卷积网络分割候选实例。在InstanceFCN中,与FCN一样的是每一个像素仍然代表了一个分类器,但是不像FCN对一个类别只产生一个分数图,而是计算一组实例敏感分数图(Instance-sensitive score map),其中每一个像素是一个目标实例相对位置的分类器。
如下图,产生了9个分数图,分别对应了3x3网格中的每一个相对位置,可以看到6号分数图在目标实例的右边有着较高的分数。通过组合这些分数图的输出可以得到目标的实例分割结果。
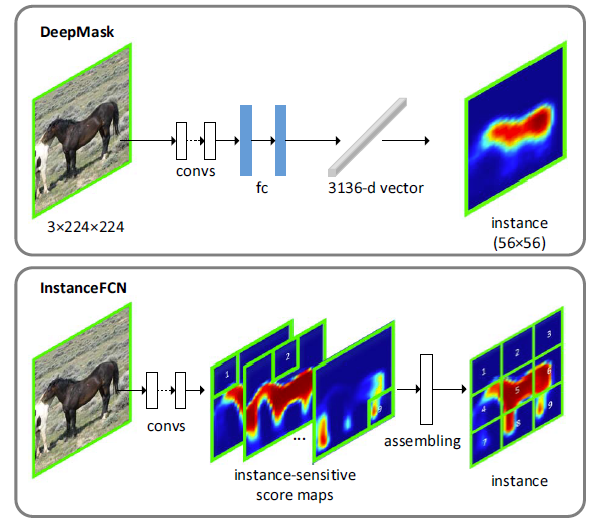
在这篇文章之前,还有DeepMask实例分割。DeepMask是一种实例分割proposal方法,将一个图像滑动窗映射到$m^2-d$的向量(比如,m为56),这个向量代表了$m \times m$分辨率的掩码,这是通过$m^2-d$的全连接层计算的。与DeepMask不同,InstanceFCN没有与掩码尺寸相关的层,并且每一个像素是低维的分类器。
Instance-sensitive FCNs for Segment Proposal
From FCN to InstanceFCN
Instance-sensitive score maps
对于FCN语义分割来说,如果图像中就只有一个实例,那么语义分割的结果就很好地表示了实例掩码,但是像上面的图中,两个目标有部分重合的区域,FCN是无法区分开的,所以只要能把这种重叠部分区分好,那么问题其实就解决了。因此InstanceFCN基于这样的分析,引入了相对位置的概念。既然原始的FCN中,每一个输出像素是一个类别的分类器,那么提出一种新的FCN,每一个输出的像素是实例中相对位置的分类器。文中定义了9($k^2$)个相对位置,所以FCN输出9个实例敏感的分数图。
Instance assembling module
上面的实例敏感分数图只是代表了实例中相对位置的分数,还没有得到实例分割结果,因此后续还需要一个实例组合模块(Instance assembling module)。这个模块没有可学习参数,具体要做的事情就是复制粘贴:在这组分数图上使用一个$m \times m$的滑动窗,在这个滑动窗中,每一个$\frac m k \times \frac m k$的子窗口直接从相应的分数图中同样的子窗口复制那一部分数值。之后这组子窗口按照相对位置拼起来就得到了$m \times m$的结果。
Local Coherence
局部一致性的意思是,对一幅自然图像中的一个像素而言,当两个相邻的窗口中进行评估时,预测结果极有可能是相同的。当窗口被平移一小步时,并不需要完全地重新计算预测。如下图,把一个蓝色的窗口平移一小步,得到平移后的窗口为红色,图像中相同的那个黄色像素点将会得到相同的预测,因为它是从相同的分数图中复制而来的(除了在相对位置的划分区附近的几个像素 )。这就允许当掩码分辨率为$m^2$时,可以保存大量的参数。这与DeepMask的机制不同,DeepMask基于滑动的全连接层,当窗口平移一步时,图像中同一个像素是由全连接层两个不同的通道预测的。所以当在两个相邻窗口评估时,同一个像素的预测通常不会相同。
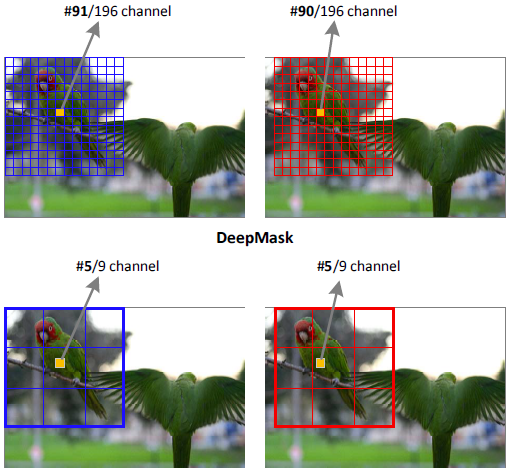
通过利用局部一致性,网络中卷积层的尺寸和维度就独立于掩码分辨率了。这不仅降低了掩码预测层的计算代价,而且更重要的是减少了掩码回归的参数量,减少对于小数据集过拟合的风险。
Algorithm and Implementation
Network architecture
- 使用VGG-16做特征提取,其中13个卷积层可以应用在任意尺寸图像上。
- 做了一些修改:将最大池化层pool4的stride从2改为1,conv5_1到conv5_3中相应的卷积核通过“hole algorithm”调整。经过调整后的VGG网络conv5_3特征图的有效stride是8。减小的stride直接决定了分数图的分辨率。
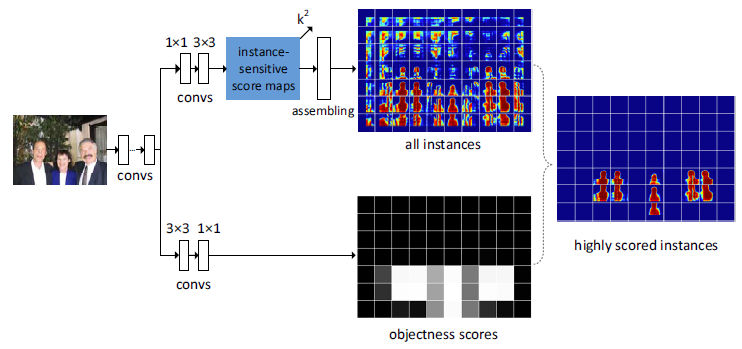
- 在特征图的顶部,有两个全卷积分支,一个用来估计分割实例,另一个用来为实例打分。
- 对于第一个分支,采用512-d的卷积层(带有ReLu激活函数)去转换特征,然后使用3x3的卷积层去生成一组实例敏感的分数图,最后的卷积层有$k^2$个输出通道,对应着$k^2$个实例敏感的分数图。在实例敏感的分数图顶部,使用组合模块在分辨率为$m \times m$(m为21)的滑动窗中生成目标实例。
- 对于第二个分支,使用3x3的512-d的卷积层后面跟随一个1x1的卷积层。这个1x1的卷积层是逐像素的逻辑回归,用于分类以这个像素为中心的滑动窗是实例或不是实例。所以这个分支的输出是目标(objectness)分数图,其中一个分数对应生成一个实例的滑动窗。
Training
网络是端到端进行训练的,前向传播中,计算一组实例敏感的分数图以及目标分数图,之后,采样256个滑动窗,从这些滑动窗中组合实例用于计算损失函数,损失函数定义如下:
$$\sum_i(L(p_i, p^*_i) + \sum_j L(S_{i,j}, S^*_{i,j}))$$
其中,$i$是采样窗口的索引,$p_i$是窗口中实例的预测分数,如果窗口中是正样本,那么这个分数就为1,否则为0。$S_i$是窗口中组合的分割实例,$S_i^*$是分割实例的ground truth,$j$是窗口中像素的索引,$L$是逻辑回归损失。256个采样窗口中,正负样本比例是1:1。
Inference
推断过程就是对输入图像生成实例敏感分数图以及目标分数图,之后组合模块通过在分数图上应用滑动窗产生每一个位置的分割实例。每一个实例与目标分数图中的一个分数相关联。在多尺度问题上, 是把图像缩放到不同尺度,然后计算每一个尺度上的实例。最终得到的是二值掩码,应用NMS生成最后的分割proposal。
Experiments
定量分析可以参考论文,这里展示一些效果图。

简评
主要的关键点在于实例敏感的分数图,其实类似与R-FCN中提到的位置敏感分数图,但是R-FCN是在这篇文章之后出的。之所以可以使用这些分数图解决实例分割问题,是因为同一个像素点,如果它在实例中的相对位置的不同,那么它将会对应着不同编号的分数图,所以它在不同的实例中,有着不同的语义。总之,这是一个很好的思路,不过作者所说的端对端仅仅是针对分割proposal而言的,如果要得到实例的类别,其实是需要后续的网络处理的,这两个任务之间是分离的。之后作者又出了一篇FCIS,与这篇文章不同的是,FCIS是RPN+Position Sensitive ROI Pooling + Inside/Outside Score maps ,因为这2种分数图的联合,使得分割与检测同步进行,整个网络是端对端的。