这篇文章发表于2016年,提出了第一个端到端的实例分割模型,同时检测和分割实例。通过引入位置敏感的内/外分数图,底层的卷积表达被两个子任务以及所有的感兴趣区域完全地共享。
Introduction
FCN接受一幅任意尺寸的图像,通过一系列的卷积,最终为每一个像素产生关于每个类别的概率,从而实现了简单、高效、端对端的语义分割。但是FCN并不能解决实例分割任务,因为卷积具有平移不变性,同一个像素点接收的响应(类别分数)是相同的,与它在上下文中的相对位置无关。简单点说,因为卷积的平移不变性,图像中物体无论在哪个位置,它所对应的类别是固定的,所以语义分割中,每个像素点只能对应一种语义。实例分割任务需要在区域级上操作,并且同一个像素在不同的区域中具有不同的语义,比如在这个区域中,它可能是前景,但在另一个区域中可能就是背景。
现有的方法解决这个问题主要是通过在3个stage中采取不同的子网络:
- 利用FCN在整幅图像上生成中间特征图和共享特征图
- 使用一个池化层将共享特征图中的每一个RoI处理成固定尺寸的特征图
- 在最后的网络中使用一个或多个全连接层把每一个RoI的特征图转换为每一个RoI的掩码。
这种方案存在几个问题:
- RoI池化将每一个RoI转换为相同的尺度,feature warping和resizing损失了空间细节,得到的特征表达降低了分割的精确度。特别是对大目标而言,其特征图会被缩小后再处理,那么一些小的部件可能就会丢失。
- 在不使用局部权重共享的情况下,全连接层参数是过多的。训练和测试的代价也会较大。
FCIS中针对上面的问题处理方式是:
- 去掉RoI池化,使用位置敏感分数图,将一组不同位置的分数图通过组合,得到RoI的特征
- 底层的特征是完全共享的,所有的RoI都是直接从计算好的特征图中取出来;全连接层被去掉,使用了全卷积网络,参数量减少。
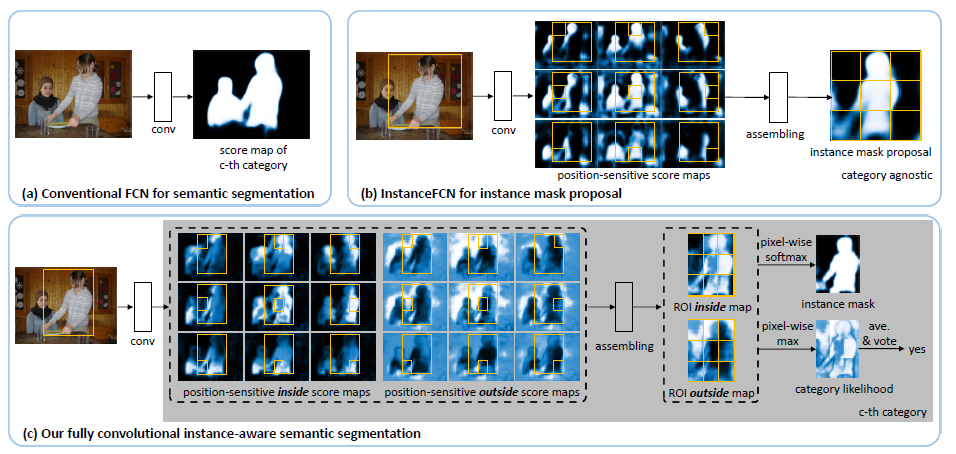
下图中(a)是传统的用于语义分割的FCN,得到一个分数图,用来预测每一个像素所属的类别,这种方法并不知道像素是什么实例的。(b)是Instance-sensitive fully convolutional networks这篇文章的方法,InstanceFCN使用3x3的位置敏感分数图编码相对位置信息。它的下游网络对segment proposal分类。检测和分割是分离的,不是端对端的。(c)是FCIS,位置敏感的内/外分数图被联合使用,同时进行目标分割和检测。
Our Approach
Position sensitive Score Map Parameterization
在FCN中,分类器被用于产生每一个像素属于目标类别的概率,这是平移不变的,而且其所属的目标实例是未知的。那么对于相邻的两个目标,有时候一个像素在这个目标上可能是前景,但是在另一个目标上可能就是背景了,在不同的位置对应着不同的语义。所以像FCN那样使用一个分数图并不足以区分这种情形。
为了引入平移同变性,InstanceFCN中采用了$k^2$个位置敏感分数图,如图中共9个分数图。一组分数图对应的是RoI中不同位置的分数,比如第一个分数图对应了RoI中均匀划分的3x3的网格中左上角的那一块的分数。
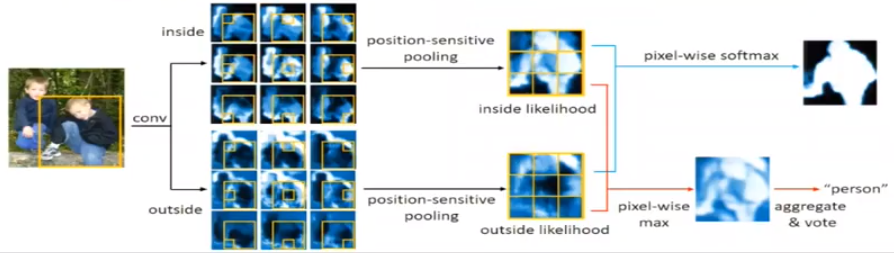
为什么使用位置敏感分数图可以带来平移同变性呢?比如下图中两个人物分别对应着两个不同的RoI,红点部分是两个RoI重叠的部分,这幅图像产生的inside分数图是左边的9个,被两个RoI共享。位置敏感分数图中同一个像素点,在不同的相对位置,有着不同的分数。对每个RoI,分别使用位置敏感的RoI池化组成最终的RoI的inside/outside分数图。可以看到红色点对应的分数是不一样的,它在左边人物的RoI中前景分数很高(白),而在右边人物的RoI中前景分数就很低。同一个像素在不同的位置对应着不同的语义,这就是平移同变性。

Joint Mask Prediction and Classification
使用位置敏感分数图可以解决实例分割问题,但是实例的类别是未知的,过去的方法都是使用一个子网络去解决分类问题,FCIS中是通过2类分数图inside/outside score map来联合解决分割和分类问题的:
- inside score map:像素在某个相对位置属于某个目标实例,并且在目标边界内
- outside score map:像素在某个相对位置属于某个目标实例,并且在目标边界外
同一组位置敏感分数图,以及底层卷积被目标检测和分割两个子任务共享。对于RoI中的每一个像素,有两个任务:检测,它是否属于某一个目标的bounding box(detection+/detection-);分割,它是否属于某个实例,即是否在实例边界内(segmentation+/segmentation-)。简单的方式是独立地训练两个分类器,两个分数图是分开使用的,这种情况下,两个分类器是两个1x1的卷积层。
但是FCIS通过一个联合规则(joint formulation),融合了inside/outside score map这两种分数图,如果一个像素在一个RoI中是前景,那么inside分数就会比较高,而outside分数就会比较低。对一个像素来说总共有三种情形:
- 高的inside分数和低的outside分数:即detection+,segmentation+
- 低的inside分数和高的outside分数:detection+,segmentation-
- 低的inside分数和低的outside分数:detection-,segmentation-
这里并没有出现两种分数都很高的情况,作者没有提到,其实也可以这么理解,因为对于一个像素来说,只可能是上面的3种情况中的一种,两者分数都很高代表了这个像素点在实例边界内,同时在实例边界外,这是不可能的。

两种分数图之后会被联合使用:
- 对于检测,使用逐像素的max操作区分前两种情况和第三种情况。之后跟随一个在所有类别上的softmax操作,然后通过对所有像素的概率进行平均池化,得到整个RoI的检测分数。
- 对于分割,在每个像素上使用softmax区分第一种和第二种情况,RoI的前景掩码(概率值)是每个像素对于每个类别的分割分数的并集。
- 检测和分割这两个分数集合来自两个1x1卷积层。inside/outside分类器被联合训练,因为它们接收来自于分割和检测损失的梯度。
这种方法有许多可取的特性:每一个RoI组分没有自由参数;特征图是通过一个FCN产生的,没有涉及到特征的warping,缩放以及全连接层;所有的特征和分数图都遵守原始图像的高宽比;FCN的局部权重共享特性被保持并且作为一种正则化机制;所有的RoI计算是简单、快速的,甚至可以是忽略不计的。
An End to End Solution
FCIS使用ResNet-101,去掉最后用于分类的全连接层,只训练前面的卷积层,最后的特征图是2048通道的,通过1x1的卷积降维到1024。ResNet中,特征图分辨率的stride是32,对于实例分割来说太过粗略了。为了降低stride,使用了”hole algorithm”,conv5第一个block的stride从2降到1,所以最终特征stride为16。为了保持感受野,conv5所有的卷积层dilation都设置为2。
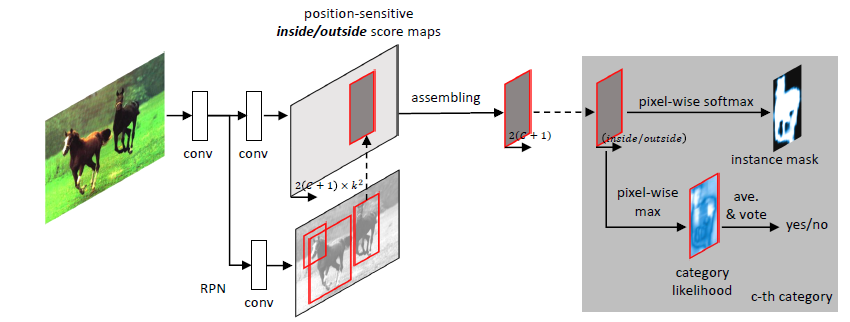
下图是网络结构示意图:
- 首先是基础网络提取特征,作者为了与其他方法公平比较,在conv4之后使用RPN生成RoIs。RPN也是全卷积的。
- 使用1x1的卷积从conv5的特征图生成$2k^2(C+1)$的分数图:C类+1个背景;默认地,$k=7$,每一类2组分数图,每一组都是$k^2$个。因为最终的特征图相比原始图像缩小了16倍,因此在特征图上,每一个RoI相当于被投影进16倍小的区域中。
- 并列的1x1的卷积层,通道数为$4k^2$,添加在conv5特征图后用来估计bounding box的偏移量。
- 随后经过前面提到的联合公式,将每一组的$k^2$个分数图进行组合,得到最终的内/外分数图。
- 最后对内/外分数图进行逐像素的softmax得到实例掩码;逐像素的max->softmax->平均池化->投票,得到RoI所属的类别。
Inference
- 对一张输入图像,RPN产生300个分数最高的RoI,然后它们通过bounding box分支产生精修过的新的300个RoI。对每一个RoI,最终得到它的分类分数和所有类别的前景掩码(概率)。
- 使用IoU阈值为0.3的NMS,过滤重叠的RoI。剩下的按照最高的类别分数进行分类。
- 前景的掩码通过掩码投票获得。具体来说,对一个RoI,从600个RoI中找到所有的与它IoU高于0.5的RoIs,根据像素对应的分类分数加权求平均,然后二值化作为输出。
Training
- 正负样本:如果一个RoI的box与最近的ground truth的IoU大于0.5,则这个RoI为正样本,否则为负样本
- 每个RoI有3项权重相等的损失:
- C+1类的softmax检测损失
- softmax分割损失:ground truth和预测的前景掩码之间的损失,累加RoI所有像素上的损失然后通过RoI的尺寸进行标准化。
- bbox回归损失。后两项损失只计算正样本的。
- 训练图像缩放到短边为600。
- OHEM,每个mini-batch,一幅图像的300个RoI被进行前向传播,选择其中损失最高的128个RoI反向传播它们的误差梯度。
- 对于RPN,默认使用9个anchor(3个尺度,3个高宽比)。COCO数据集多用3个anchor
- 整个网络是联合训练的,实现特征共享
简评
FCIS可以说是RPN + Position Sensitive ROI Pooling + Inside/Outside Score maps,将这几部分融合进一个网络,进行端到端的实例分割。主要的亮点就是 Inside/Outside分数图,将检测和分割两种任务关联了起来。