这篇文章建立在Mask R-CNN上,提出了一种新的半监督训练和权重迁移方程。在类别数量很大的训练集上每个图像中的实例都有box标记,但是只有一小部分有掩码标记,这篇文章提出的方法可以在这样的数据集上训练实例分割模型。主要的贡献就是训练Mask R-CNN去检测和分割3000种实例,box标记使用Visual Genome数据集,掩码标记来自于COCO数据集的80个类别。
Introduction
实例分割可以预测出前景的分割掩码,如Mask R-CNN。但实际上,分割系统涉及的类别很少,而且目前的分割算法要求强大的监督学习,但是新类别的掩码标记代价太高,因此这种监督学习会受到限制。相比之下,bounding box的标记代价较低,所以问题来了:对于所有类别,在没有完整的掩码标记的情况下,是否有可能训练出一个高性能的实例分割模型呢?这篇文章就是在这样的动机下提出了一种部分监督的(partially supervised)实例分割任务,并且设计一种新的迁移学习方法去解决上面提到的问题。
partially supervised实例分割任务:
- 给定一个感兴趣的类别集合,其中一小部分子集拥有实例分割掩码,然而其他类别只有bounding box标记。
- 实例分割算法应该利用这些数据拟合出一个模型,它能够分割出所有属于感兴趣目标类别的实例。
把那些同时具有bounding box标价和掩码标记的样本称为强标记样本(strongly annotated examples),而只有bounding box标记的样本称为弱标记样本(weakly annotated examples)。
为了实现这种实例分割,提出了一种构建在Mask R-CNN上的迁移学习方法。Mask R-CNN将实例分割任务分解成两个子任务:bounding box目标检测和掩码预测。每个子任务都有一个专门的网络”head”,使用联合训练。本文提出的方法背后的直觉是:一旦经过训练,bounding box head的参数为每一个目标类别编码一个embedding,使得对于这一个类别的视觉信息迁移到分割任务的head上。
为此,设计了一个参数化的权重迁移方程,该方程是关于一个类别的bounding box检测参数的函数,通过该方程可以预测出该类别的实例分割参数。权重迁移方程可以在Mask R-CNN上进行端对端的训练,使用类别标签和掩码标记作为监督。预测过程,权重迁移方程为每一个类别预测实例分割参数,因此使得模型可以分割所有类别的目标,包括那些训练时没有掩码的类别。
作者对两种设置进行了探索:
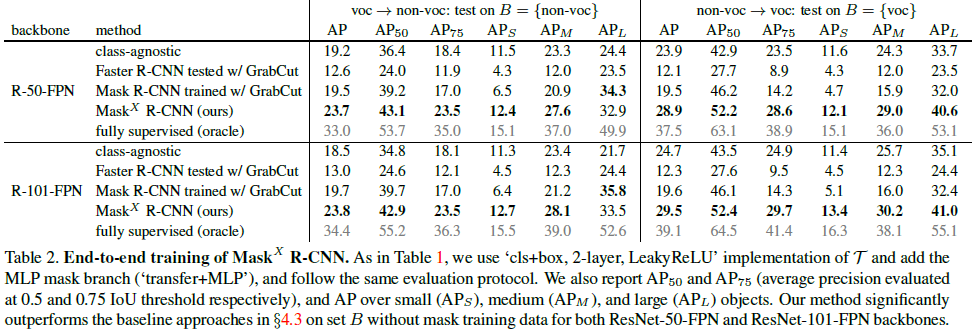
- 使用COCO数据集模拟半监督实例分割任务,具体过程是:将COCO数据集分类两个不相交的子集,一个子集拥有掩码标记,另一个子集只能访问bounding box标记。实验表明,在没有训练掩码的类别上,本文的方法将掩码AP值提高了40%。
- 使用Visual Genome(VG)数据集的3000个类别,训练大规模的实例分割模型。这个数据集对于大部分目标类别都有bounding box标记,但是定量评估较难,因为很多类别在语义上是重叠的,比如是近义词;并且标记并不详尽,因此精确率和召回率都很难衡量;除此之外VG数据集没有实例掩码。因此,本文使用VG数据集提供大规模实例分割模型的定性输出。
下图中绿色是训练过程中有掩码标记的类别,红色的是训练中只有bounding box标记的类别。
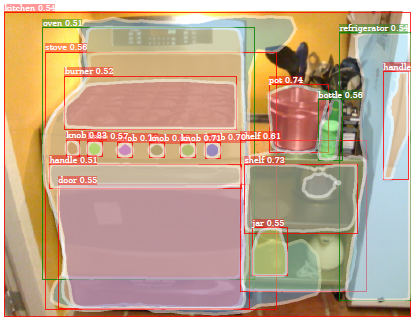
目标类别也许可以通过视觉空间的连续嵌入向量模拟,在这个空间中临近的向量通常在外观或语义本体上很接近。这篇文章的工作中,Mask R-CNN的box head参数包括了类别特定的外观信息,可以被视为是通过训练bounding box目标检测任务学习到的嵌入向量。类嵌入向量通过与视觉相关类共享外观信息使得本文中模型的迁移学习可行。本文的核心思想就是利用迁移学习将bounding box检测学习的知识迁移到实例分割任务中,使得对于没有掩码标记的类别,也能够很好地分割出实例。
Learning to Segment Every Thing
设$C$为目标类别集合,对于这个集合要训练一个实例分割模型。大多数已有的方法假设这个集合中所有训练样本都被标记了实例掩码。本文放松了这个要求,假设$C=A \bigcup B$,其中集合A有掩码,而集合B只有bounding box标记,B集合中类别的样本关于实例分割任务是弱标记的。
实例分割模型比如Mask R-CNN,它有bounding box检测和掩码预测两个部分,本文提出$Mask^X R-CNN$方法将模型bounding box检测器获取的类别特定的信息迁移到实例掩码预测中。
Mask Prediction Using Weight Transfer
Mask R-CNN可以被视为对Faster R-CNN检测模型的扩增,它带有一个小的FCN掩码预测分支。在预测阶段,掩码分支对每一个检测到的目标预测它的分割掩码,在训练阶段,掩码分支和Faster R-CNN中的标准的bounding box head联合训练。
在Mask R-CNN中,bounding box分支和掩码分支的最后一层都包含了类别特定的参数,分别用来实现bounding box分类和实例掩码预测。如下图:
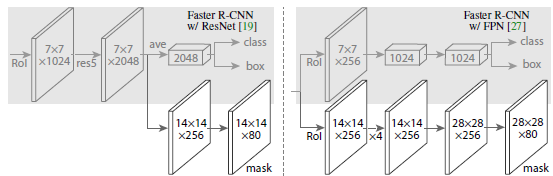
本文不再独立地学习类别特定的bounding box参数和掩码参数,而是使用通用的、类别无关的权重迁移方程作为整个模型的一部分进行联合训练,从一个类别的bounding box参数去预测它的掩码参数。
对于一个给定类别$c$,设$w_{det}^c$为bounding box head最后一层类别特定的目标检测权重,$w_{seg}^c$为掩码分支类别特定的掩码权重。与Mask R-CNN不同,这里掩码权重不再作为模型参数,而是使用一个通用的权重预测方程$\tau$来对它参数化:
$$w_{seg}^c=\tau(w_{det}^c;\theta)$$
这里$\theta$是类别无关的可学习参数。同一个迁移方程被用到任何其他类别上,因此$\theta$的设置应该使得迁移方程对训练过程中没有掩码的那些类别具有很好的泛化性能。作者在这里认为这种泛化是可能的,因为类别特定的检测权重$w_{det}^c$可以被视为这个类别的一种基于外观的视觉嵌入(Visual embeddings)。这里我个人并不是非常理解视觉嵌入相关的知识,有待挖掘。
继续说这个迁移方程,它是用一个小的全连接神经网络实现的。下图阐明了权重迁移方程拟合Mask R-CNN到形成$Mask^X R-CNN$的过程,阴影部分是Mask R-CNN:
- 前面与Mask R-CNN相同,图像输入给ConvNet,然后经过RPN和RoIAlign,而后是两个分支,box head和mask head
- 不再单独地学习掩码参数$w_{seg}$,而是将它相应的box检测参数$w_{det}$输入给权重迁移方程,从而获得一个类别的掩码权重
- 对于训练,迁移方程只需要集合A中类别的掩码,但是在测试阶段,它可以应用在$A \bigcup B$的所有类别上
- 使用一个互补的类别无关的全连接多层感知机(MLP)扩增了mask head,这其实与Mask R-CNN中的FCN mask head是一种互补,后面会解释这种互补。
一个细节:bounding box head包含两种检测权重:RoI分类权重$w_{cls}^c$和bounding box回归权重$w_{box}^c$。这篇文章的实验只使用一种权重:$w_{det}^c=w_{cls}^c~or~w_{det}^c=w_{box}^c$,或者使用两种权重的拼接:$w_{det}^c=[w_{cls}^c,w_{box}^c]$。
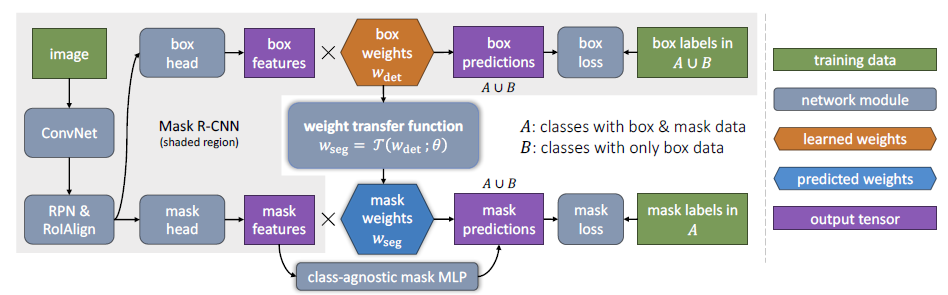
说一下个人的理解:Mask R-CNN中做的是检测到一个box,然后利用类别特定的分割权重去预测这个box里实例的掩码。这两部分是并行分支,检测权重和分割权重都是类别特定的,分别编码了各自的特征空间,并且在监督学习下进行。在缺少某些类别的掩码标记时,就学习不到这个类别的掩码权重,从而无法预测到这类实例的掩码。这个问题在这篇文章中得到了很好的解决:作者加入一个小的全连接神经网络(迁移方程)打通了两个并行分支,学习的是这两种特征空间编码之间的映射,尽管分割任务的学习缺少某些类别的掩码标记,可是通过已有的数据,只要学习到这种映射关系,那么自然地就可以得到那些没有掩码标记的类别的分割权重。
Training
训练bounding box head使用的是在$A \bigcup B$ 所有类别上的box 检测损失,但是只使用A中类别的掩码损失训练mask head。提出两种方案:
- 逐阶段训练(stage-wise):Mask R-CNN可以被看做是Faster R-CNN加一个掩码分支,因此分成检测训练和分割训练,第一个阶段只使用$A \bigcup B$中的bounding box标记训练Faster R-CNN;第二个阶段保持卷积特征和box head固定,训练mask head。这样的话,每一个类别特定的检测权重$w_{det}^c$可以被视为固定的类嵌入向量(class embedding vectors),它在训练的第二阶段不需要更新。
- 端到端的联合训练:在Mask R-CNN中已经证明多任务训练比单独训练每一个任务会有更好的性能,前面提到的逐阶段训练方式可能会导致性能低下。理论上也可以直接使用两个集合的box损失和集合A的掩码损失,进行反向传播,然而这也许会导致在集合A与B之间类别特定的检测权重会有差异性。因为对于一个类别$c$如果它属于A,只有$w_{det}^c$会接收到掩码损失经过权重迁移方程回传的梯度。也就是说,A中那些类别的检测权重既能接收到bounding box损失的梯度,又能接收到掩码损失的梯度;而B中那些类别的检测权重只能收到bounding box损失的梯度。但是目的是要在两个集合之间得到同样的检测权重,从而使得在集合A上训练的类别特定的分割权重$w_{seg}^c$很好地泛化到集合B。因此采取了一个简单的方法:在反向传播掩码损失时,阻止关于$w_{det}^c$的梯度,也就是说,回传掩码损失的梯度时,只计算预测掩码权重关于迁移方程参数$\theta$的梯度,而不计算关于$w_{det}^c$的梯度:$w_{seg}^c=\tau(StopGrad(w_{det}^c);\theta)$。
Extension: Fused FCN+MLP Mask Heads
在Mask R-CNN中使用类别无关的FCN head,将其作为baseline。
Mask R-CNN中考虑了两种mask head:一是FCN head,使用全卷积网络预测MxM的掩码;二是MLP head,使用全连接层组成的多层感知机预测掩码,这点与DeepMask更相似。在Mask R-CNN中,FCN head具有更高的mask AP值,然而这两种设计可能是互补的。直觉上,MLP掩码预测也许更好地捕获了目标的“要点”(全局),而FCN掩码预测也许更好地捕获了目标的细节(局部),比如目标边界。基础这样的观察,提出一种改进,将类别无关的FCN和权重迁移方程以及类别无关的MLP掩码预测融合。
融合K类类别无关的掩码预测(1XMxM)和类别特定的掩码预测(KxMxM)时,这两个分数被加到最后的KxMxM的输出上。这里,类别无关的掩码预测会被平铺K次。然后,这个KxMxM的掩码分数经过一个sigmoid单元被变为每一类的掩码概率,再被缩放到实际的bounding box尺寸作为最终那个bounding box的实例掩码。
Experiments
Results and Comparison of Our Full Method
作者做了很多对比试验,最终选择使用迁移方程+MLP以及类别无关的FCN head融合的模型,其中迁移方程的实现使用两种权重的拼接,2层的MLP,LeakyReLU作为激活函数,整个网络采取端对端的训练。
Large-Scale Instance Segmentation
$Mask^X R-CNN$模型的训练,使用VG数据集,包含108077张图像,超过7000类同义词集合,标记了bounding box,但是没有掩码。训练中,选择3000个最常见的同义词集合作为类别集合$A \bigcup B$用来实例分割,它覆盖了COCO中的80个类别。因为这两个数据集有大量的重叠,因此在VG上训练时只采用没有在COCOval2017中出现的那些,VG中剩下的图像作为验证集。把VG中与COCO重叠的80个类作为集合A,带有掩码标记;剩下的2920个类别作为集合B,只有bounding box。
作者最终训练出了一个可以分割3000类实例的$Mask^X R-CNN$,如题“Learning to Segment Every Thing”。