这篇论文提出了一种概念简单,灵活且通用的目标实例分割框架,在检测出图像中目标的同时,生成每一个实例的掩码(
mask)。对Faster R-CNN进行扩展,通过添加与已存在的bounding box回归平行的一个分支,预测目标掩码,因而称为Mask R-CNN。这种框架训练简单,容易应用到其他任务,比如目标检测,人体关键点检测。
Introduction
实例分割的挑战性在于要求正确地检测出图像中的所有目标,同时精确地分割每一个实例。这其中包含两点内容:
- 目标检测:检测出目标的
bounding box,并且给出所属类别; - 语义分割(
semantic segmentation):分类每一个像素到一个固定集合,不用区分实例。
Mask R-CNN对Faster R-CNN进行了扩展,在Faster R-CNN分类和回归分支的基础上,添加了一个分支网络去预测每一个RoI的分割掩码,把这个分支称为掩码分支。掩码分支是应用在每一个RoI上的一个小的FCN,以像素到像素的方式(pixel-to-pixel)预测分割掩码。
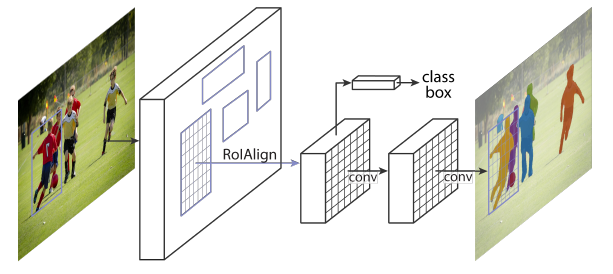
Faster R-CNN在网络的输入和输出之间没有设计像素到像素的对齐。在how RoIPool文中提到:实际上,应用到目标上的核心操作执行的是粗略的空间量化特征提取。为了修正错位,本文提出了RoIAlign,可以保留准确的空间位置,这个改变使得掩码的准确率相对提高了10%到50%。解耦掩码和分类也至关重要,本文对每个类别独立地预测二值掩码,这样不会跨类别竞争,同时依赖于网络的RoI分类分支去预测类别。
模型在GPU上运行每帧200ms,在8 GPU的机器上训练COCO数据集花费了一到两天。最后,通过COCO关键点数据集上的人体姿态估计任务来展示框架的通用性。通过将每个关键点视为一位有效编码(one-hot),即所有关键点编码成一个序列,但只有一个是1,其余都是0。只需要很少的修改,Mask R-CNN可以应用于人体关键点检测。不需要额外的技巧,Mask R-CNN超过了COCO 2016人体关键点检测比赛的冠军,同时运行速度可达5FPS。
Related Work
早前的实例分割方法受R-CNN有效性的推动,基于分割proposal,也就是先提取分割候选区,然后进行分类,分割先于分类的执行。本文的方法是同时预测掩码和类别,更加简单和灵活。
FCIS(fully convolutional instance segmentation)用全卷积预测一系列位置敏感的输出通道,这些通道同时处理目标分类,目标检测和掩码,这使系统速度变得更快。但FCIS在重叠实例上出现系统错误,并产生虚假边缘。
另一类方法受语义分割的推动,将同类别的像素划分到不同实例中,这是一种分割先行的策略。Mask R-CNN与其相反,基于实例先行的策略(segmentation-first strategy)。
Mask R-CNN
Mask R-CNN在Faster R-CNN上加了一个分支,因此有三个输出:目标类别、bounding box、目标掩码。但是掩码输出与其他输出不同,需要提取目标更精细的空间布局。Mask R-CNN中关键的部分是像素到像素的对齐,这在Fast/Faster R-CNN里是缺失的。
首先回归一下Faster R-CNN:它包含两个阶段,第一阶段使用RPN提取候选的目标bounding box,第二阶段本质上是Fast R-CNN,使用RoI pooling从候选区域中提取特征,实现分类并得到最终的bounding box。
Mask R-CNN也是两个阶段:第一阶段与Faster R-CNN相同,RPN提取候选目标bounding box;第二阶段,除了并行地预测类别和候选框偏移,还输出每一个RoI的二值掩码(binary mask)。
损失函数
- 多任务损失:$$L=L_{cls}+L_{box}+L_{mask}$$ 掩码分支对每一个感兴趣区域产生$Km^2$维的输出,
K是类别数目,K个分辨率为m×m的二值掩码也就是针对每一个类别产生了一个掩码。 - 对每一个像素应用
sigmoid,所以掩码损失就是平均二分类交叉熵损失。如果一个RoI对应的ground truth是第k类,那么计算掩码损失时,只考虑第k个掩码,其他类的掩码对损失没有贡献。 - 掩码损失的定义允许网络为每个类别独立预测二值掩码。使用专门的分类分支去预测类别标签,类别标签用来选择输出掩码。
掩码表达
- 掩码编码了输入目标的空间布局。掩码的空间结构,可以通过卷积产生的那种像素到像素的对应关系来提取。
- 使用
FCN为每个RoI预测一个m×m的掩码。这允许掩码分支中的每个层显式的保持m×m的目标空间布局,而不会将其缩成缺少空间维度的向量表示。 - 像素到像素的对应需要
RoI特征(它们本身就是小特征图)被很好地对齐,以准确地保留显式的像素空间对应关系。
RoI Align
首先说明为什么需要对齐,下图中左边是ground truth,右边是对左边的完全模仿,需要保持位置和尺度都一致。平移同变性(translation equivariance)就是输入的改变要使输出也响应这种变化。
- 分类要求平移不变的表达,无论目标位置在图中如何改变,输出都是那个标签
- 实例分割要求同变性:具体的来说,就是平移了目标,就要平移掩码;缩放了目标就要缩放掩码
全卷积网络FCN具有平移同变性,而卷积神经网络中由于全连接层或者全局池化层,会导致平移不变。
在Faster R-CNN中,提取一张完整图像的feature map,输入RPN里提取proposal,在进行RoI pooling前,要根据RPN给出的proposal信息在基础网络提取出的整个feature map上找到每个proposal对应的那一块feature map,具体的做法是:根据RPN给出的边框回归坐标,除以尺度因子16,因为vgg16基础网络四次池化缩放了16倍。这里必然会造成坐标计算会出现浮点数,而Faster R-CNN里对这个是进行了舍入,这是一次对平移同变性的破坏;同样的问题出现在后面的RoI pooling中,因为要得到固定尺寸的输出,所以对RoI对应的那块feature map划分了网格,也会出现划分时,对宽高做除法出现浮点数,这里和前面一样,简单粗暴地进行了舍入操作,这是第二次对平移同变性的破坏。如下图,网格的划分是不均匀的:
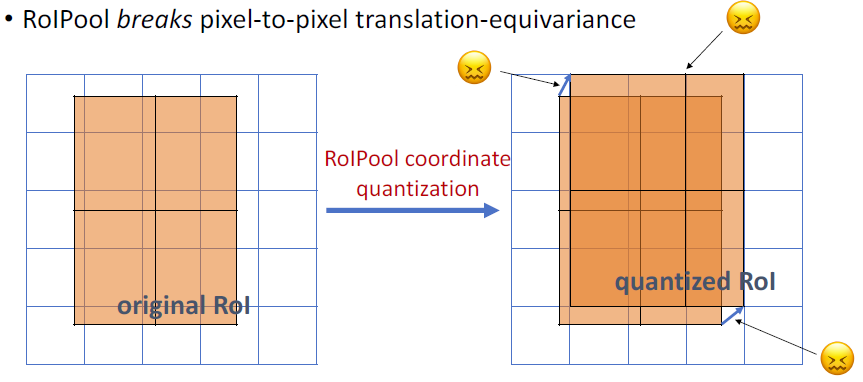
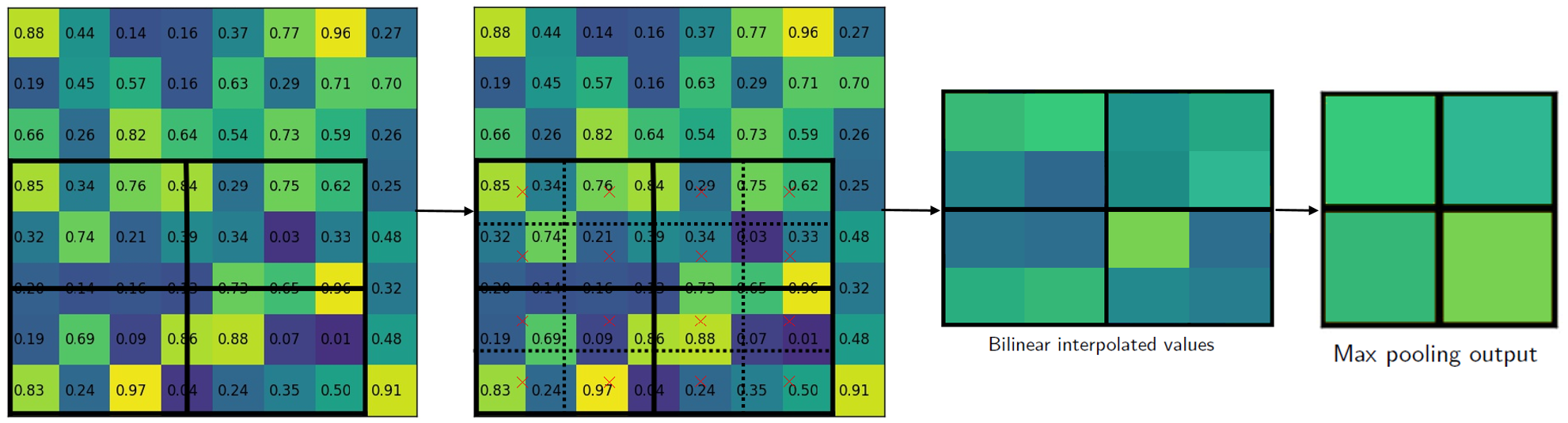
总之,Faster R-CNN破坏了像素到像素之间的这种平移同变性。RoI Align就是要在RoI之前和之后保持这种平移同变性,避免对RoI边界和里面的网格做量化。如下图:
- 针对输入的
feature map找到对应的RoI,是通过$x/16$而不是像Faster R-CNN中$[x/16]$,$[\cdot]$代表舍入操作。所以可以看到第一幅图中RoI并没有落在整数的坐标上。 - 对
RoI划分为2x2的网格(根据输出要求),每个小的网格里采样4个点,使用双线性插值根据临近的网格点计算这4个点的值,最后再对每一个网格进行最大池化或平均池化得到最终2x2的输出。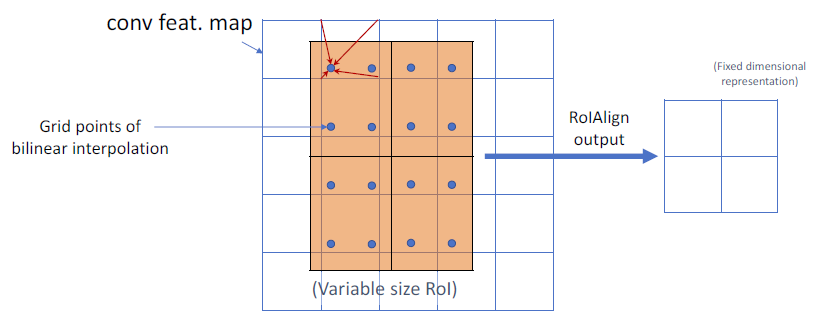
network
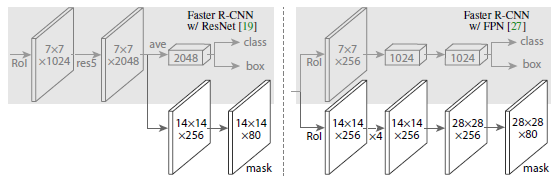
下图中,是两个不同的network head,左图是ResNet C4,右边是FPN主干,这两种结构上都添加了一个掩码分支,反卷积使用2x2的卷积核,stride为2;除了输出层是1x1的卷积,其他部分的卷积都是3x3的。
实现细节
- 掩码损失只定义在正的
RoI上 - 输入图像被缩放到短边为
800,每个图像采样N个RoI(ResNet的N=64,FPN的N=512),batch size = 2,正负样本的比例为1:3。 - 测试中对于
ResNet架构,生成300个proposal,FPN则是1000。 - 将得分最高的
100个检测框输入掩码分支,对每一个RoI预测出K个掩码,但是最终只根据分类分支的预测结果选择相应的那一个类别的掩码。 mxm的浮点数掩码输出随后被缩放到RoI尺寸,然后以0.5的阈值进行二值化。