这篇文章发表在
CVPR2016上,提出位置敏感分数图(position-sensitive score map)去权衡图像分类中的平移不变性和目标检测中的平移变换性这种两难的境地。
Introduction
比较流行的关于目标检测的深度网络可以通过ROI pooling layer分成两个子网络:
a shared, “fully convolutional” subnetwork independent of RoIs.(独立于ROI的共享的、全卷积的子网络)an RoI-wise subnetwork that does not share computation.(不共享计算的ROI-wise(作用于各自RoI的)子网络)
工程上的图像分类结构(如Alexnet和VGG Nets)被设计为两个子网络——1个卷积子网络后面跟随1个空间池化层和多个全连接层。因此,图像分类网络中最后的空间池化层自然变成了目标检测网络中的RoI池化层。
目前最好的图像分类网络,例如残差网络(ResNets)和GoogleNets都是用fully convolutional设计的。在目标检测中都使用卷积层去构建一个共享的卷积网络是一件十分自然的事。但是这种简单的方法分类效果很好,检测效果却很差。为了解决这个问题,ResNet文中Faster R-CNN的RoI pooling layer被不自然地插入在两个卷积层之间,这创建出一个更深的RoI-wise子网络,改善了精度,但是各个RoI计算不共享所以速度慢。
图像分类任务更加喜欢平移不变性,图像中目标的移动不应该被区分看待。因此具有平移不变性的全卷积网络结构在分类上表现更佳。另一方面,目标检测需要一定程度上具有平移变化的定位表达。在一个候选框中目标的平移应该产生有意义的响应,这种响应可以描述候选框与目标重合的好坏程度。
这篇文章提出了基于区域的全卷积网络 (R-FCN),为给FCN引入平移变化,用一组专门的卷积层构建位置敏感分数图 (position-sensitive score maps)。每个位置敏感的score map编码感兴趣区域的相对空间位置信息。在FCN顶部增加1个位置敏感的RoI pooling layer来监管这些分数图,这个层后面没有卷积或全连接层。
R-FCN
Overview
网络采用ResNet-101作为基础网络产生feature map,之后使用Faster R-CNN中的RPN提取候选区域,RPN本身就是全卷积网络,RPN和R-FCN之间共享特征。在R-FCN中,所有可以学习的权重层都是卷积层,并且是在整幅图上计算的。整个流程可以简单概括为:输入图像->基础网络提取feature map->专门的卷积层提取位置敏感的score map->位置敏感的RoI pooling->对结果投票(取平均)进而得到预测结果
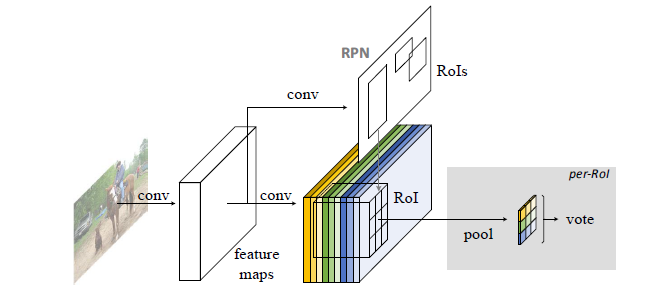
- 首先输入图像经过基础网络得到整张图像的
feature map,然后RPN给出RoIs。 - 得到
feature map后,再经过最后一个卷积层,使用$k^2(C+1)$个卷积核为每一个类别产生$k^2$个position-sensitive score maps,所以对于C类的目标再加上一个背景类,输出层的通道数为:$k^2(C+1)$。 - $k^2$个
score map与k×k个空间网格相对应。网格描述了相对空间位置,例如k=3,则对应9个位置(左上,左中,…右下)。 R-FCN的最后是位置敏感的RoI池化层(position-sensitive RoI pooling layer)。这一层聚合上一个卷积层的输出,并且为每一个RoI生成得分,根据得分对这些感兴趣区域分类。
位置敏感的RoI池化是选择性池化:k=3,对每个类别生成了9个score map,每一个score map的通道是21。
- 将
RoI对应的9x21通道的score map取出,每一个score map都对应了一个空间位置,共9个空间位置。但这里并不是对RoI对应的每一个score map进行池化,然后将结果组合,而是将RoI对应的那块score map划分为3x3的网格。(Fast R-CNN里的RoI pooling也是将feature map划分为网格) - 从每个
score map对应的空间位置上只取出一个小网格进行池化(文中使用的是平均池化,但最大池化也没问题)。例如下图中最后得到了3x3的feature map,其左上角(其实只是一个数值)黄色的部分就是对前一层第一个黄色的score map中RoI里3x3的网格中的左上角网格进行池化的结果。所以最后的feature map其实每一个位置的元素都是从前一层负责这个空间位置的score map里该空间位置的网格池化得来的。对所有的score map这样操作,再聚合起来就得到最后的k×kx(C+1)的feature map。 - 所有颜色的小方块就是一些位置敏感的分数,然后这些分数在
RoI上投票(文中是取平均)得到一个C+1维的响应,之后使用softmax计算类别的得分判断是哪一类目标。
上述就完成了目标分类,回归位置采用的是相似的做法,在生成score map的最后一个卷积层处,也同时进行了另一路卷积,生成$4k^2$的feature map用于bounding box回归;然后针对每一个RoI使用位置敏感的RoI pooling通过平均池化产生4-d的向量。这里实际上是类别无关的位置回归,实际上也可以通过产生$4k^2(C+1)$的feature map得到类别特定的位置回归。
下图是可视化结果:如果一个候选框精确地与目标重合,$k^2$个bin中大多数都会被强烈地激活,投票分数就会高;相反,如果候选框没有正确地与目标重合,则RoI中的$k^2$个bin里,有一部分则不会被激活,投票分数就会低。

Backbone architecture
本文中R-FCN是基于ResNet-101的,100个卷积层后跟随全局平均池化,然后加一个1000类的全连接层。
改动:移除了average pooling层和全连接层,只是用卷积层去计算feature map。ResNet-101中最后的卷积块是2048-d的,为了降维附加了一个随机初始化的1024-d的1×1的卷积层。然后使用k^2(C+1)通道的卷积层生成score map。