为了解决现有
CNN需要固定输入大小的问题,提出了SPP-net,使得针对任意尺寸的图像生成固定长度的特征表示。输入一张图,只需要对整张图进行一次feature map的计算,避免了像R-CNN那样重复地计算卷积特征。SPP-net不仅可以应用在分类任务上,而且在检测任务上也有很大的性能提升。
Introduction
在CNN的训练和测试阶段都有一个技术问题:CNN需要固定输入图像的尺寸,这些图片或者经过裁切(crop)或者经过变形缩放(warp),都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。
如下图所示,上面是CNN一般的做法,对不符合网络输入大小的图像直接进行crop或warp,下面是SPP-net的工作方式。SPP-net加在最后一个卷积层的输出后面,使得不同输入尺寸的图像在经过前面的卷积池化过程后,再经过SPP-net,得到相同大小的feature map,最后再经过全连接层进行分类。

Spatital Pyramid Pooling
CNN为什么需要固定输入尺寸?卷积层是不需要输入固定大小的图片,而且还可以生成任意大小的特征图,只是全连接层需要固定大小的输入。因此,固定输入大小约束仅来源于全连接层。在本文中提出了Spatial Pyramid Pooling layer来解决这一问题,输入任意尺寸的图像,SPP layer对特征进行池化并生成固定大小的输出,以输入给全连接层或分类器。
- 以
AlexNet为例,经CNN得到Conv5输出的任意尺寸的Feature map,图中256是conv5卷积核的数量。 - 将最后一个池化层
pool5替代成SPP layer。以不同网格来提取特征,分别是4x4,2x2,1x1,将这三张网格放到feature map上,就可以得到16+4+1=21种不同的块(Spatial bins),对这21个块应用max pooling,每个块就提取出一个特征值,这样就组成了21维特征向量。
这种用不同大小的格子划分feature map,然后对每一个块应用最大池化,将池化后的特征拼接成一个固定维度的特征的方式就是空间金字塔池化。
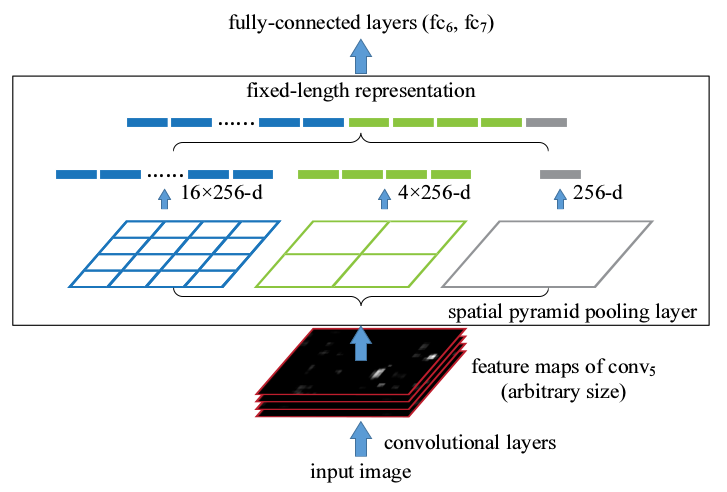
总结而言,当网络输入一张任意大小的图片,进行卷积、池化,直到即将与全连接层连接的时候,就要使用空间金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的意义(不同度特征提取出固定大小的特征向量)。
Training
理论上,无论输入什么尺寸的图像,都可以用标准的反向传播训练。但是实际上由于GPU实现中,更适合在固定尺寸的输入图像上,因此提出了一些训练策略。
Single-size training:使用固定的224x224的输入,是从原始图像中裁切得到的,目的是为了数据扩增;对于给定的输入尺寸,可以预先计算出空间金字塔池化需要的bin size,假如feature map是axa的大小,那么在SPP layer中,窗口尺寸$win = \frac a n$,步长$stride = \frac a n$。Multi-size training:考虑两种输入,180x180和224x224,这里不再用裁切,而是直接进行缩放,比如把224x224的图像直接缩放为180x180,它们之间的区别只是分辨率不同。实现两个固定输入尺寸的网络,训练过程中先在1号网络上训练一个epoch,然后用它的权重去初始化2号网络,训练下一个epoch;如此转换训练。通过共享两种尺寸输入的网络参数,实现了不同输入尺寸的SPP-Net的训练。
这样single/multi-size的训练只是在训练中,预测阶段,直接将不同尺寸的图像输入给SPP-Net。
SPP-net for Object Detection
对于R-CNN,整个过程是:
- 首先通过选择性搜索,对待检测的图片进行搜索出约
2000个候选窗口。 - 把这
2000个候选框都缩放到227x227,然后分别输入CNN中,利用CNN对每个proposal进行提取特征向量。 - 把上面每个候选窗口的对应特征向量,利用
SVM算法进行分类识别。
可以看出R-CNN的计算量是非常大的,因为2k个候选窗口都要输入到CNN中,分别进行特征提取。
而对于SPP-Net,整个过程是:
- 首先通过选择性搜索,对待检测的图片生成
2000个候选窗口。这一步和R-CNN一样。 - 特征提取阶段。与
R-CNN不同,把整张待检测的图片,输入CNN中,进行一次特征提取,得到整个图像的feature maps(可能是在多尺度下),然后在feature maps中找到各个候选框对应的区域,对各个候选框采用空间金字塔池化,提取出固定长度的特征向量。因为SPP-Net只需要对整张图片进行一次特征提取,速度会大大提升。文中是几十到一百倍以上。 - 最后一步也是和
R-CNN一样,采用SVM算法进行特征向量分类识别。
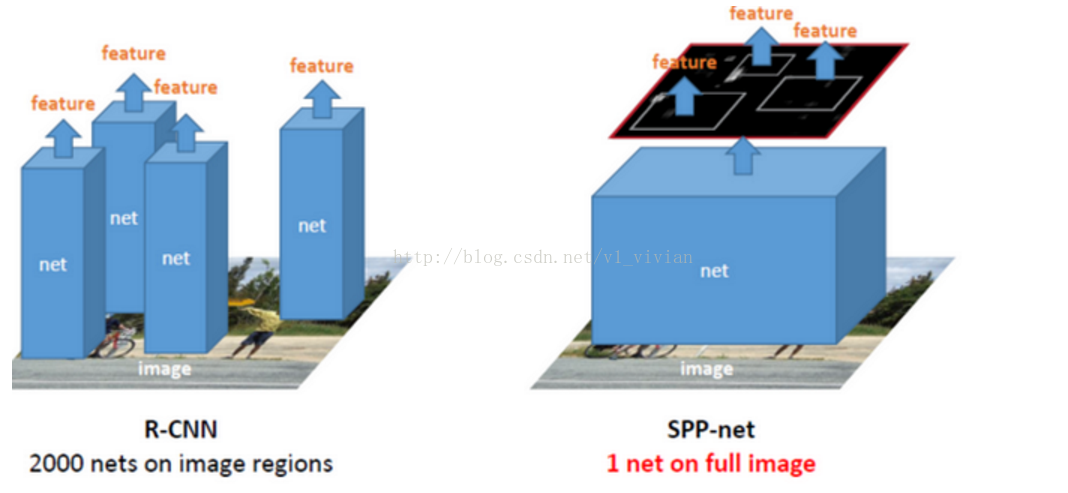
下图为SPP-net进行目标检测的完整步骤:

Mapping a Window to Feature Maps
SPP-Net在提取完整图像的feature map后,要将候选框的位置映射到feature map中得到对应特征。候选框是在原始图像上得到的,而feature maps是经过原始图片卷积、下采样等一系列操作后得到的,所以feature maps的大小和原始图片的大小是不同的。
假设$(x,y)$是原始图像上的坐标点,$(x’,y’)$是特征图上的坐标,S是CNN中所有的步长的乘积,那么左上角的点转换公式如下:$$x’ = \frac x S + 1$$
右下角的点转换公式为:$$x’ = \frac x S - 1$$