这篇文章发表于2018年,现有的目标检测框架通常都是使用图像分类网络作为基础网络,但是图像分类与目标检测任务之间有几点不同:(1)像FPN,RetinaNet为了实现不同尺度目标的检测,图像分类网络通常涉及额外的阶段;(2)大的下采样因子带来的大的感受野,这对图像分类任务有利,但是会降低检测任务的性能。因此,这篇文章提出的DetNet是一种新的专门为目标检测任务设计的backbone网络。
Introduction
最近的检测器比如FPN中图像分类网络涉及了额外的stage,DetNet也一样。具体有两个创新点:
- 不同于传统的图像分类预训练模型,DetNet即使在额外的stage依然能够保持较高的特征图空间分辨率。
- 高分辨率的特征图因为计算和内存代价给构建深度神经网络带来更多的挑战。为了解决这个问题,采用了低复杂度膨胀瓶颈结构(dilated bottleneck structure)。
通常,浅层特征分辨率高,但是感受野小,而深层特征分辨率低,感受野大。通过这些改进,DetNet不仅可以保持高分辨率特征图,而且可以保持大的感受野,这两点对于检测任务都很重要。
DetNet
Motivation
图像分类网络的设计原则对于目标检测中的定位过程是不利的,因为特征图的空间分辨率会逐渐的降低,比如VGG的stride是32。下图中A是使用传统的backbone的FPN,B是用于图像分类的传统backbone,C是DetNet。可以看出,在与FPN相同的一些stage上,DetNet具有更高的分辨率。(第一个stage未表示在图中)。
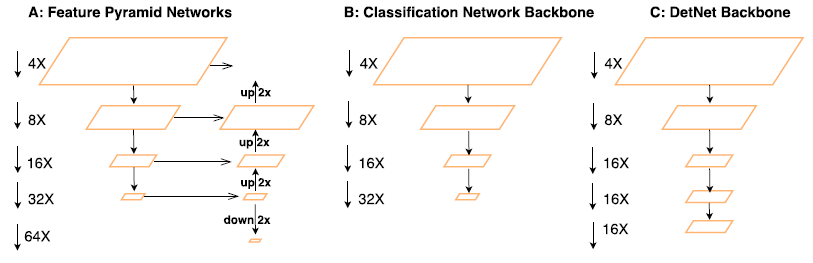
网络stage的数量是不同的。图B中,典型的分类网络设计5个stage,每一个stage使用2x的池化或者stride为2的卷积进行下采样。所以输出的特征图空间尺寸相比输入图像有32x的下采样。FPN采取了更多的stage,额外的stage P6被用于更大的目标,RetinaNet添加了P6,P7两个stage。很显然,这些额外的阶段是没有在ImageNet数据集上预训练过的。
大目标的弱可见性。stride为32的特征图语义信息更强,具有大的感受野,因此在图像分类中取得了好的结果。但是对于目标的定位是有害的,在FPN中使用更深的层去预测大目标,对于回归目标位置来说这些目标的边界太模糊了。如果再用上额外的stage,结果会更糟糕。
小目标的不可见性。大的stride导致小目标的丢失。由于空间分辨率的降低和大的上下文信息的集成,小目标的信息很容易被削弱。FPN在较浅的层预测小目标,然而浅层语义信息不强,不足以识别出目标的类别,因此FPN通过采用自底向上的旁路连接弱化了这个问题。但是,如果小目标在更深的层被丢失了,这些上下文线索也将同时丢失。
DetNet就是为解决这些问题而提出的。具有以下几点特性:
- stage的数量是直接为目标检测设计的,额外的stage也可以在分类数据集上进行预训练
- 即使比传统的图像分类有更多的stage,比如stage6或stage7,但是依然能保持特征图具有较高的分辨率,同时具有较大的感受野
DetNet Design
前4个stage与ResNet-50相同。其他的实现细节:
引入额外的stage,比如P6,将被用于目标检测,和FPN中P6作用类似。同时在stage4之后固定空间分辨率为16x的下采样
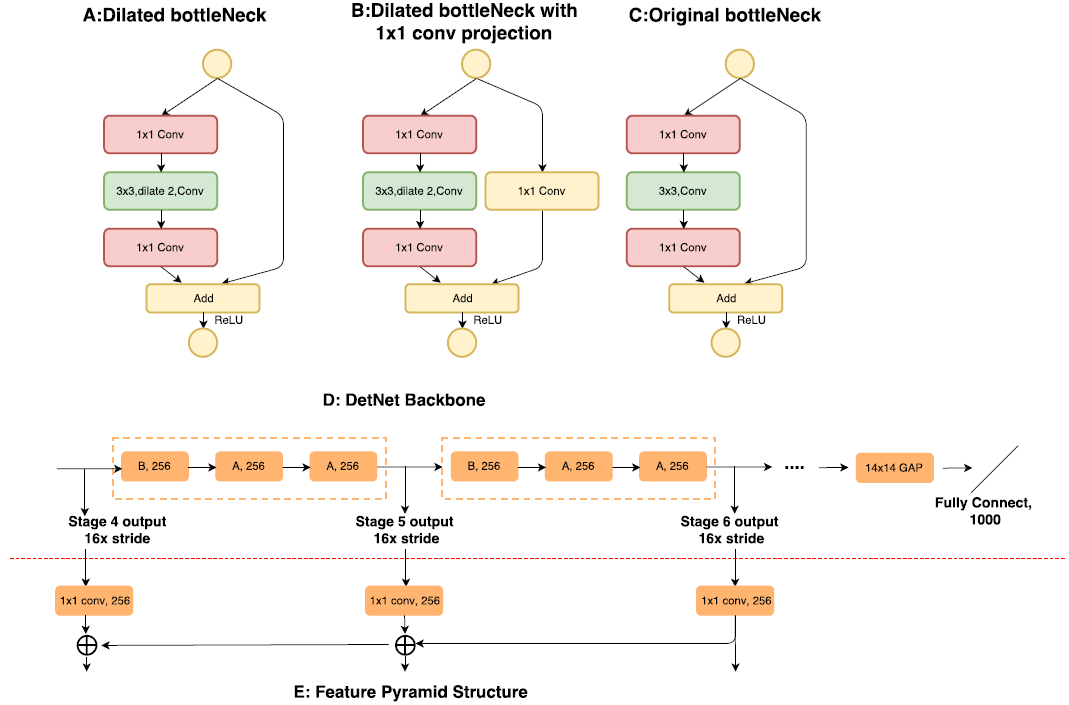
因为固定了stage4之后的空间分辨率,为了添加新的stage,采取了一个膨胀瓶颈结构,在每一个stage的开始,使用1x1的卷积投影,如下面的图B。作者发现图B的模型对于多阶段的检测器比如FPN很重要。A,B是在DetNet实验中用到的不同bottleneck block。在传统的ResNet中,当特征图的空间分辨率没有改变时,bottleneck结构中的映射应该是简单的恒等映射,如图A。而DetNet中使用了1x1的卷积。作者认为即使在空间尺寸没有改变的情况下,1x1的卷积投影对于创建一个新的stage是有效的。实验结果也证明了mAP上会有提升。
使用带膨胀的瓶颈网络作为基础的网络block有效地增大感受野。由于膨胀卷积仍然是费时的,stage5和stage6与stage4保持相同的通道(对于瓶颈block是256的输入通道)。这与传统的backbone设计不同,传统的是在后续的stage加倍通道数
上图中“dilate 2”表示使用膨胀卷积,膨胀卷积如下图。其中2表示卷积核中点与点之间的距离,下图中距离为1。
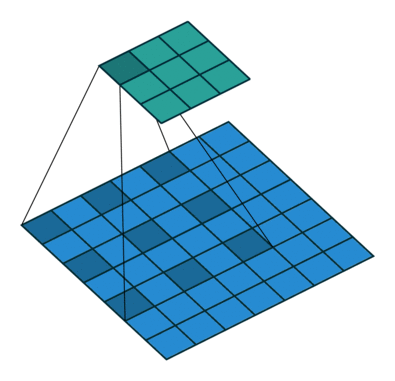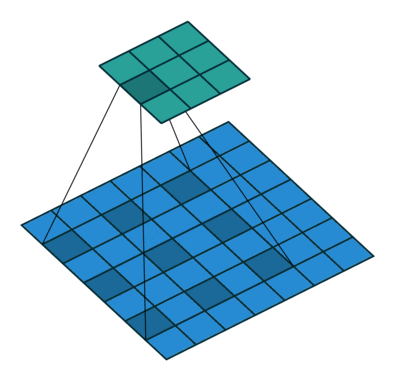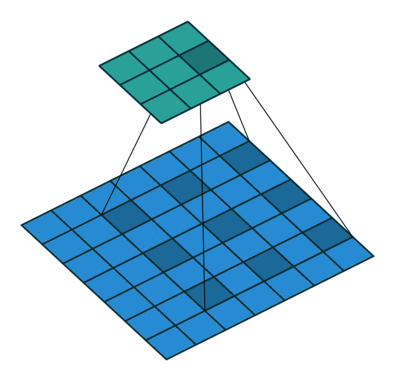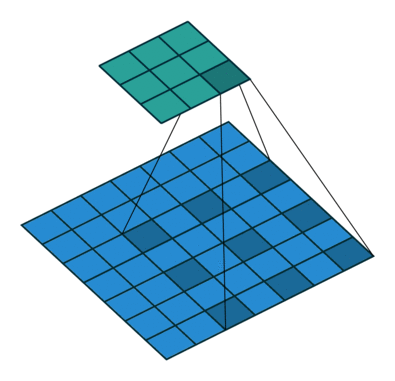
作者使用FPN作为baseline,把PFN的backbone改为DetNet,因为在ResNet的stage4后没有降低空间分辨率,因此在FPN的旁路连接上,只需简单的求和,如图D与E。
Experiments
Detector training and inference
- 图像的短边被缩放为800,长边限制在1333,batch size为16,同一批样本图像通过在右下方填充0得到相同大小。
- 通过在ImageNet上预训练的模型,进行网络初始化,在对检测器进行微调时,固定backbone中stage1的参数,BN层也是固定。
- 对于proposal的生成,提取分数最高的12000个,然后进行NMS获取2000个RoI用于训练。在测试阶段,使用6000/1000的设置:6000个最高分的proposal,NMS后1000个RoI。除此之外,还用到了Mask R-CNN中的RoI-Align。
Main Results
- 作者在ImageNet上训练了DetNet,与ResNet-50相比,DetNet多了一个额外的stage6,并且参数量也更大。但是可以看出,分类结果上,DetNet高于ResNet-50,同时比参数量更大的ResNet-101效果还要好。
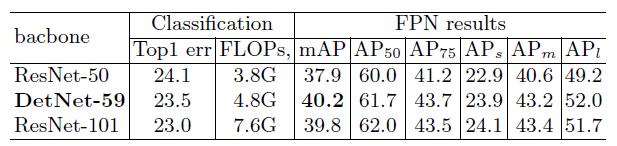
- 接下来,作者从头训练了分别基于DetNet-59和ResNet-50的FPN,DetNet效果也更好。

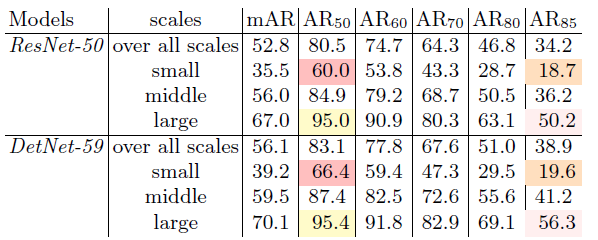
DetNet在大目标的定位上有更好的性能,AP85那一列展示了DetNet-59比ResNet-50高出了5.5。
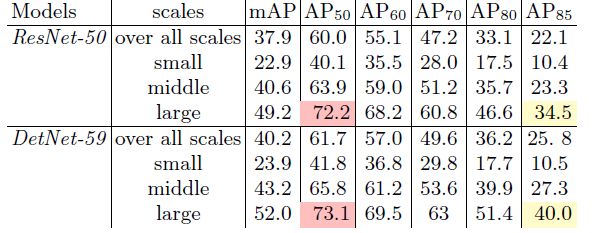
DetNet在找到丢失的小目标上也做的很好。在下表中小目标的平均召回率上可以看出DetNet的优势。然而在$AR_{85}$的小目标检测性能上可以看到,DetNet与ResNet相当,毕竟基于ResNet-50的FPN在检测小目标上已经使用了大的特征图。同时还可以看到$AR_{85}$的大目标检测性能,DetNet更好。这表明在DetNet有利于大目标定位。然而$AR_{50}$的大目标上性能上改善不大。总而言之,比起找到丢失的大目标,DetNet更擅长于找到精确的大目标
Comparison to State of the Art
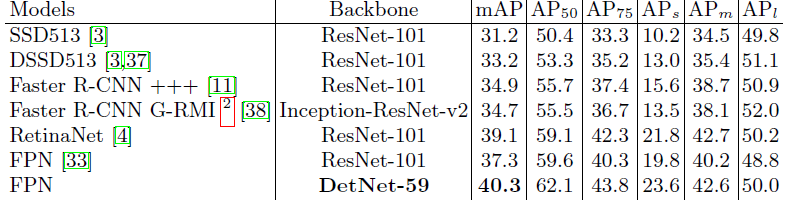
目标检测
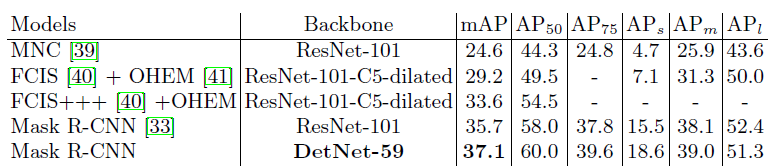
实例分割
简评
这篇文章为解决分类任务和检测任务之间的gap,而提出了DetNet作为目标检测任务的backbone,为了精确地回归目标位置保持特征空间分辨率较高,同时为了减小大的特征图带了的计算代价,使用dilated bottleneck structure+1x1的卷积投影。实验结果显示DetNet擅于找到丢失的小目标,以及准确地定位大目标,同时在实例分割任务上也表现出了好的结果。尽管证明了dilated bottleneck structure+1x1的卷积投影效果好,却没有给出充分解释,毕竟ResNet中用1x1的卷积投影是为了匹配维度,而这里stage5以后,通道数已经不变了,为何还要使用1x1的卷积投影?在如何精确定位小目标,以及寻找丢失的大目标上,DetNet并未表现出优势,这是一个值得继续改进的地方。等看到源码可能会有更新的理解。