这篇文章将额外的上下文信息引入到目标检测中,首先将ResNet-101和SSD组合,,然后利用反卷积层扩增这个组合的网络,为目标检测引入大尺度的上下文信息,提高准确率,特别是对小目标的检测。Deconvolutional single shot detector,因此简称DSSD。实验结果比R-FCN要好。
Introduction
这篇文章最大的贡献就是为目标检测引入了额外的上下文信息,从而提高了准确率。首先将ResNet-101和SSD组合,然后利用反卷积层扩增这个组合的网络,为目标检测引入大尺度的上下文信息,提高准确率,特别是对小目标的检测。但是这个思想实现起来并不容易,所以作者添加了额外的学习转换的阶段,特别是反卷积中前馈连接的模块和新输出的模块,使得这个新方法有效。
YOLO先计算一个全局的feature map,然后使用全连接层在一组固定的区域上做预测。SSD对一幅图像提取不同尺度的feature map,对这些feature map每一个位置应用一组默认框,使用卷积做预测,得到了精确度和速度之间一种好的权衡。
当考虑为目标检测提高准确度时,很自然地会想到使用更好的特征提取网络,添加更多的上下文信息,特别是对小目标,提高bounding box预测的空间分辨率。SSD是基于VGG基础网络做特征提取的,但是ResNe-101目前更好。在目标检测研究之外,有一种编码-解码(encoder-decoder )网络,其中网络中间层加入了瓶颈层(bottlenexk layer),用来对输入图像编码,后面再进行解码(就是卷积和反卷积),这样形成的宽-窄-宽的网络结构很像沙漏,FCN就是类似结构,本文就利用反卷积层实现了上下文信息的扩充。
Related Work
主要的目标检测方法SPPnet,Fast R-CNN,Faster R-CNN,R-FCN和YOLO都是使用最顶层的卷积层去学习在不同尺度下检测目标,虽然很强大,但是它给单一层带来了巨大的负担,因为要为所有可能的目标尺度和形状建模。提高检测准确率的方法主要有几种:
- 组合不同层的特征,然后利用组合的特征做预测。但是这样做增加了内存消耗,并且降低了速度。
- 使用不同层的特征预测不同尺度的目标,因为不同层特征图的点有不同的感受野,很显然高层的特征有着大的感受野适合预测大尺寸目标,底层特征有着小的感受野适合预测小尺寸目标。SSD就是这么做的,不同层预测特定尺度的目标。但是缺点是浅层的特征图语义信息少,小目标检测的性能就不太好。通过使用反卷积层和跳跃连接(skip connection,像ResNet那样)可以对反卷积的feature map加入更多语义信息,有助于小目标检测。
本文提出使用一种编码-解码的沙漏式结构在做预测前传递上下文信息。反卷积层不仅解决了在卷积神经网络中随着层数加深,feature map分辨率缩减的问题,而且为预测引入了上下文信息。
DSSD model
回归一下SSD,采用VGG作为基础网络,去掉尾部的一些层,加入了一些卷积层。下图是采用ResNet-101的SSD,如蓝色部分,SSD加入了5个额外的卷积层,ResNet-101中的conv3_x和conv5_x,以及这些添加的层,共7个层被用来为预定义的默认框预测分数和偏移量。预测的实现使用的是3x3xChannel的卷积核,一个卷积核针对一个类别分数,对于bounding box预测也是,一个卷积核针对一个坐标。
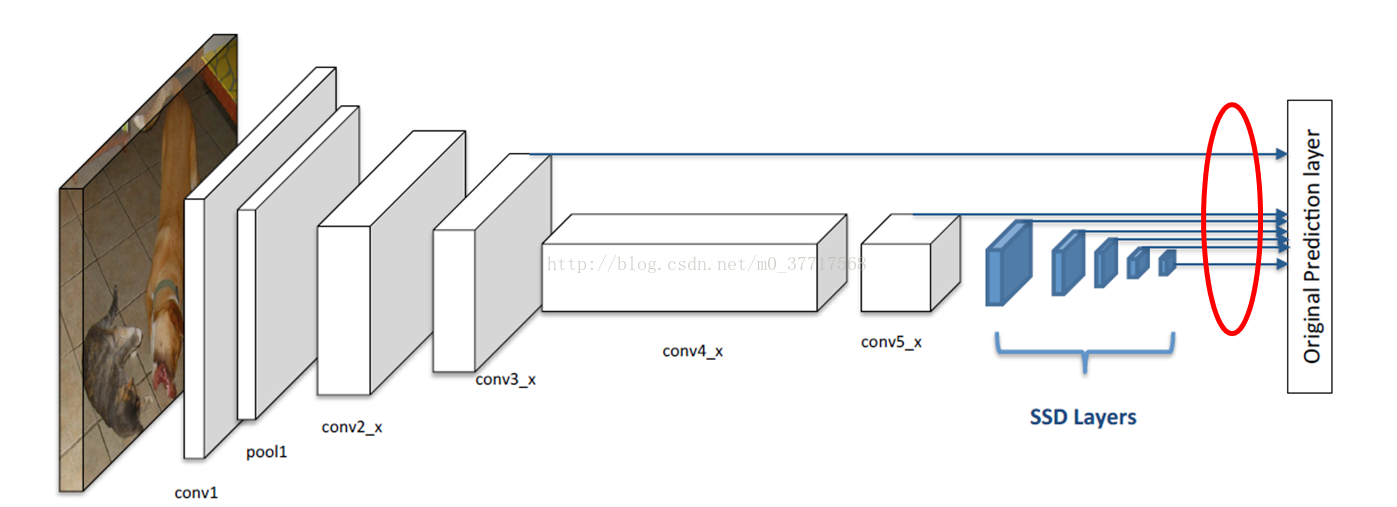
Using Residual 101 in place of VGG
第一个改进就是使用ResNet-101取代VGG作为基础网络。在conv5_x block后添加了一些层,但只是添加这些层本身并不能改善结果,因此添加了一个额外的预测模块,使用conv3_x和添加的层做预测。
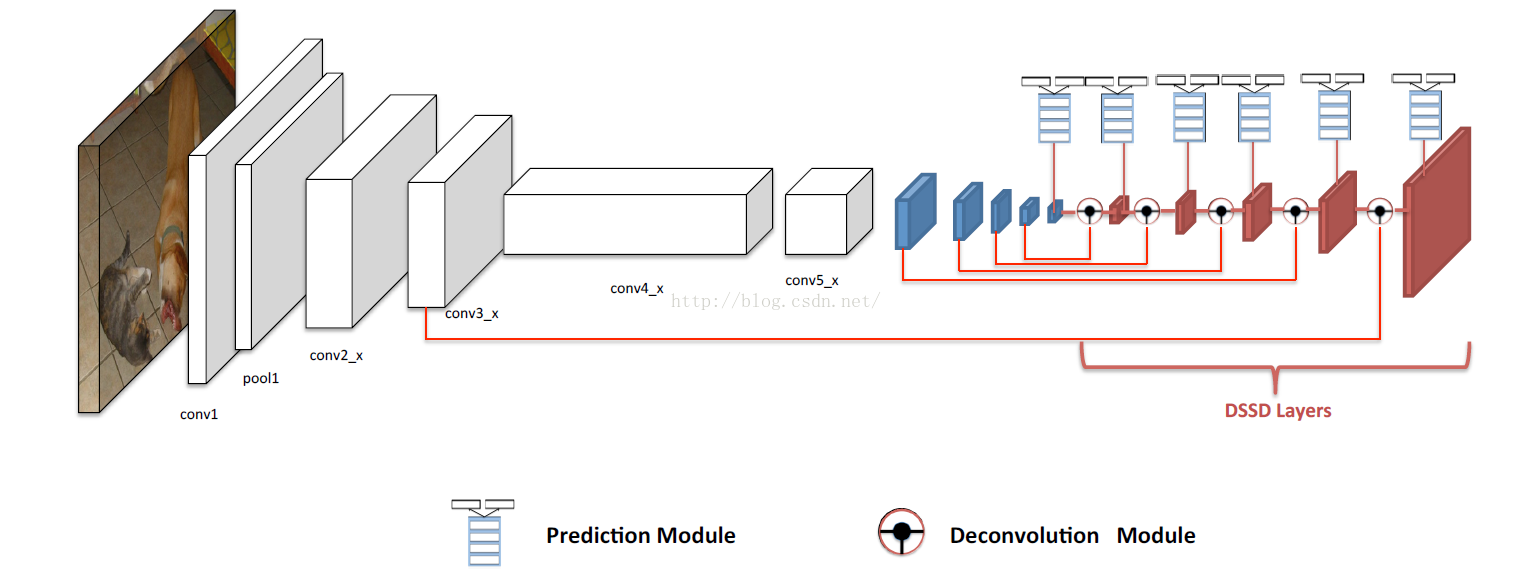
- 上图中蓝色的层就是卷积层,与SSD layer类似,是在基础网络之后添加的一些额外的层。
- 圆形为反卷积模块,这一模块一方面要对前一层的feature map做反卷积增加空间分辨率,另一方面还融合了卷积层的feature map
- 红色的层是反卷积层,是前面反卷积后的feature map和卷积层的feature map组合后的结果
Prediction module
第二个改进就是添加额外的预测模块。在SSD中,目标方程直接应用在选择的feature map上,并且由于巨大的梯度,在conv4_3上使用了L2归一化。MS-CNN指出改进每个任务的子网络有助于提升准确度,因此跟随这个思想,为预测层添加了一个残差块。作者尝试了四种变体:
- (a) 原始SSD的方法,直接在feature map上做预测
- (b) 带有跳跃连接的残差块
- (c) 相比于(b)把恒等映射换成了1x1卷积
- (d) 两个连续的残差块

这四种中(c)的效果最好,其中PM:Prediction module。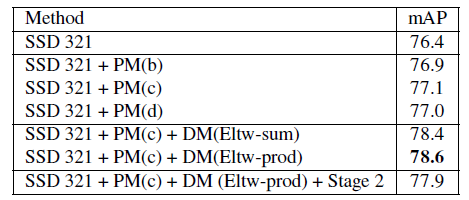
Deconvolutional SSD
为了引入更高级别的上下文信息,将检测移动到原始的SSD后面的反卷积层上,形成一个不对称的沙漏结构。这些反卷积层逐渐增大了feature map的分辨率。尽管沙漏模型(hourglass)在编码和解码阶段包含了对称的层,但是这里把解码层做的非常浅,原因有两个:
- 检测是视觉中的基本任务,可能会需要为下游任务提供信息,所以速度是一个重要的因素。
- 图像分类任务中,没有包含解码阶段的预训练模型。预训练的模型比起随机初始化的模型,可以使检测器精度更高,收敛更快。所以解码层只能随机初始化从头训练。
Deconvolution Module
为了帮助网络浅层和反卷积层的feature map做信息融合,引入了反卷积模块,如DSSD结构中圆形部分,详细的结构如下图。做了以下修改:
- 批量归一化(BN)层加在每一个卷积层之后
- 使用学习好的反卷积层代替双线性插值的上采样
最后测试了不同的组合方法:逐元素求和(element-wise sum)和逐元素乘积(element-wise product)。实验表明后者带来了最好的准确率,见Prediction module部分的表。

上图是反卷积模块,将前一层的feature map反卷积,然后与卷积层的feature map做融合(逐元素相乘),得到具有更多上下文信息和更大分辨率的feature map用来做预测。需要注意的是:
- 在反卷积模块中,所有卷积和反卷积操作,卷积个数都依赖于反卷积层的特征图的通道数
- 卷积层和ReLu激活层之间有BN层
## Training
几乎和SSD训练方式一样:
- 匹配默认框:对于每一个ground turth box,把它与IoU最好的一个默认框匹配,同时与IoU大于0.5的那些默认框匹配。未匹配的那些默认框,根据置信度损失选择高的那些,使得负样本和正样本比例为3:1。
- 最小化联合定位损失(Smooth L1)和置信度损失(softmax)
- 数据扩增:随机裁切原始图像,随机光度失真,随机翻转裁切的patch,最新版的SSD中数据扩增有助于小目标的检测,因此在DSSD中也采用了。
对先验的默认框做了一些小的改变:使用K-means,以默认框的面积作为特征,对VOC中的数据进行聚类。从2开始,逐渐增加聚类中心个数,判断误差是否减小20%,最终收敛在7个聚类中心。

因为SSD把输入图像缩放为正方形,但是大部分图像是比较宽的,所以也不奇怪bounding box是高高的。从表中可以看出,大部分box的高宽比落在1~3之间。
因为在原始的SSD中,高宽比为2和3的默认框更加有用,因此加入一个1.6的比例,然后每一个预测层使用3种高宽比的默认框:(1.6,2.0,3.0)。
# Experiments
- Residual-101在ILSVRC CLS-LOC数据集上预训练。
- 改变了conv5阶段的stride,从32改为16,提高feature map的分辨率。
- 第一个卷积层stride为2,被改为了1。
- Conv5阶段所有的卷积层卷积核尺寸大于1,增加膨胀(dilation),从1增加到2,修复由于降低stride引起的洞。

上图是PASCAL VOC2007上的测试结果,当输入的图像尺寸比较小的时候,把vgg换成resnet效果相似,但是提高输入图像的尺度的话,把vgg替换成resnet-101效果会更好,作者猜测对于Resnet这样非常深的网络,需要更大尺度的输入来让深层的feature map仍然保持较强的空间信息。更重要的是,DSSD比相应的SSD的效果要更好,DSSD对于那些具有特定背景信息的物体和小目标表现出了大的提升。
Inference Time
为了加速预测过程,使用一些公式移除了BN层,使得速度提高了1.2~1.5倍,并且降低了内存消耗:
- 卷积层的输出通过减均值,再除以方差与$\varepsilon$的和,然后缩放并且根据训练过程学习的参数做平移:$$y = scale \left( \frac {(wx+b)-\mu} {\sqrt{var} + \varepsilon} \right) + shift$$
- 卷积层的权重和偏置$$\hat w = scale \left(\frac w {\sqrt{var} + \varepsilon} \right), \hat b = scale \left(\frac {b-\mu} {\sqrt{var} + \varepsilon} \right) + shift$$
- 移除了变量相关的BN层,第一个式子概括为$$y = \hat wx + \hat b$$
DSSD因为使用了更深的基础网络,预测模块和反卷积层,以及更多的默认框,所以速度自然比SSD慢。作者提到一种加速DSSD的方式是使用简单的双线性插值上采样替代反卷积层。