这篇文章发表于2018年,比YOLOv2网络更大,但是更精确。在320x320的分辨率下,YOLOv3处理一幅图需要22ms,mAP为28.2,与SSD一样精确但是快3倍。主要的创新点有3个:类别预测上不再使用softmax而是使用独立的logistic回归,能实现多标签预测;类似于FPN,实现多尺度预测,将不同层的特征做了融合;提出更好的基础网络,加入残差块。
The Deal
Bounding Box 预测
- 跟随YOLO9000,依然使用维度聚类和anchor box。
- YOLOv3使用logistic回归为每一个bounding box预测一个目标分数,如果一个先验的box比其他box和ground truth的IoU大,这个分数就为1;如果一个先验box并不是最好的,而是与真实值的IoU超过某些阈值,就忽略掉这个预测,这点跟随Faster R-CNN,本文阈值采用0.5。
- 与Faster R-CNN不同,YOLOv3为每一个ground truth只匹配一个先验box(其实就是anchor box)。Faster R-CNN中一个ground truth匹配到两种anchor:每一个ground truth匹配到与它IoU最高的anchor,但是同时也把那些与它IoU大于0.7的anchor也当做正的,因此每一个ground truth会有多个与其匹配的anchor。
- 如果一个先验box没有被匹配到任何ground truth,那么它对于坐标回归或者类别预测没有贡献,只对目标预测(objectness)有用,也就是预测是否为目标时才有贡献。
类别预测
使用多标签预测,每个bounding box都预测可能包含的类别。但是并不使用softmax,而是使用独立的logistic回归分类器,训练中使用二分类的交叉熵损失。更加复杂的数据集Open Image Dataset有很多重叠标签,比如女性和人就是包含关系,使用softmax其实强加了一个假设:每一个box恰好有一类,但通常不是这样的。比如一个box里包含了一个“women”,这个box还应该有“person”这个标签,因此多标签方法能够更好的拟合数据。
- softmax每一个框只得到一个标签,对应分数最高的那个,不适合做多标签分类
- softmax可以被多个独立的logistic分类器替代,且准确率不会下降
多尺度预测
1 | layer filters size input output |
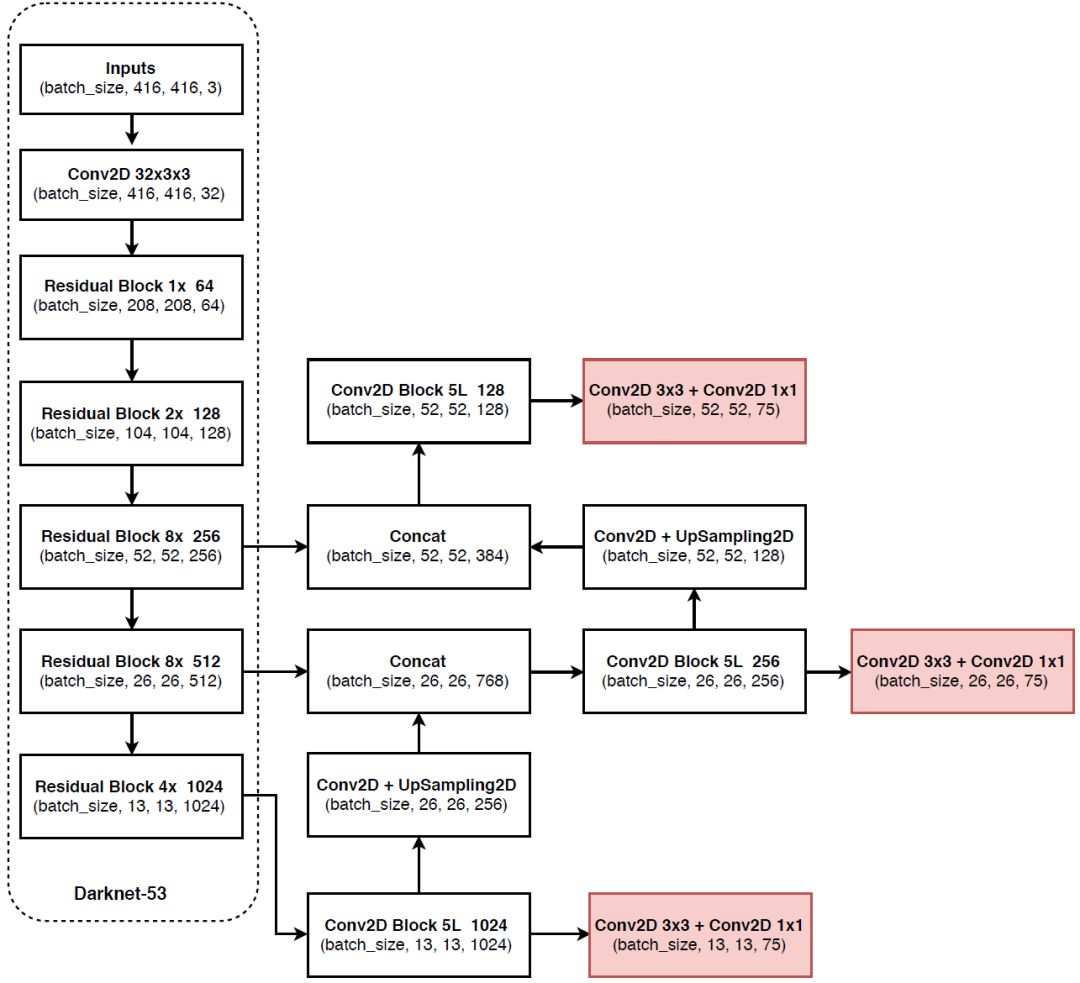
YOLOv3检测网络输入为416x416,5倍下采样后,最后一层卷积的输出是13x13。使用了一种与特征金字塔网络(FPN)相似的概念,YOLOv3在3个不同的尺度进行预测:
- 尺度1:在基础的特征提取网络上添加了几个卷积层,在最后一个卷积层输出的13x13的feature map上预测一个3-d的tensor编码bounding box,目标和类别的预测。实验中,对于COCO数据集,每一个尺度预测3个box,所以tensor的尺寸就是NxNx[3x(4+1+80)],feature map大小为NxN,每个box有4个坐标,1个目标分数,80个类别分数。
- 尺度2:提取尺度1的13x13的feature map,上采样2倍;然后在网络的浅层中取一个26x26的feature map,并把它与上采样后的feature map进行拼接(concatenation)。这个方法能够获得上采样的feature map上更加有意义的语义信息和浅层feature map上细粒度(finer-grained)的信息。添加几个卷积层去处理这个组合后的26x26x768的feature map,最终预测一个相似的tensor,但比尺度1大2倍。
- 尺度3:在尺度2的26x26的feature map基础上,上采样2倍得到52x52的feature map;取浅层的52x52的feature map做拼接,在组合后的52x52的feature map上做预测。
使用K-means聚类,只选择了9个聚类和3个尺度,然后按照聚类中心的大小平均划分3种尺度,最后3个尺度对应于尺度1的预测,以此类推。在COCO数据集上,9个聚类中心为:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
特征提取
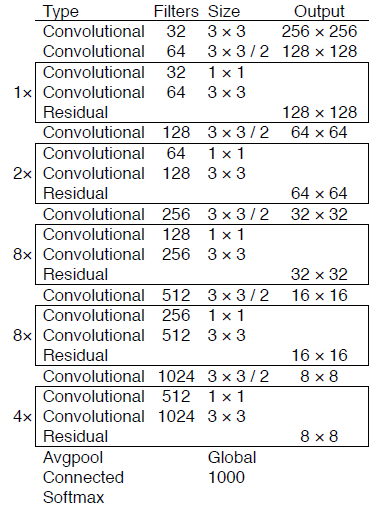
设计了一种新的特征提取网络,这个网络是YOLOv2中Darknet-19和残差网络的混合。特征提取网络连续使用3x3和1x1卷积层,但是加入了快捷连接(shortcut connection),所以明显更大一些。因为有53个卷积层,因此称其为DarkNet-53。精确率比ResNet-101更好,与ResNet-152相当,但是更高效。
训练
在完整的图像上训练,没有使用难负样本挖掘或者其他操作。使用多尺度训练,数据增强,批量归一化。
How We Do
在COCO数据集的mAP度量标准下,YOLOv3与SSD的变体DSSD相当,但仍然落后于RetinaNet,但速度更快。但是在旧的度量标准下,即IoU为0.5时的mAP,YOLOv3与RetinaNet相当,远超DSSD。但是当IoU增加时,YOLOv3的性能明显降低,说明YOLOv3其实是在努力获得与目标对齐的box。
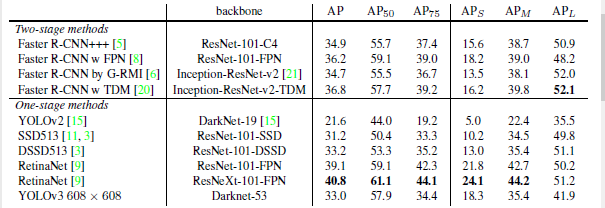
过去,YOLO在尽力解决小目标问题,现在这一情况有了逆转。当使用多标签预测时,可以看到YOLOv3,在小目标上有着相对高的AP值(APs),然而在中等和大目标上性能相对较差。
Things We Tried That Didn’t Work
- anchor box偏移量预测:降低了模型的稳定性
- 使用线性激活取代逻辑回归激活函数直接预测x,y偏移量:mAP下降了几个点
- Focal loss:降低了2个点的mAP,可能是因为YOLOv3对Focal loss尽力解决的问题已经足够鲁棒。因为YOLOv3有独立的目标分数预测和条件类概率预测。
- 双IoU阈值和:Faster R-CNN在训练中使用了2个IoU阈值,anchor box与ground truth的IoU超过0.7的也作为正样本,而[0.3,0.7]的被忽略掉。小于0.3的作为负样本。尝试在YOLOv3中这样做,但是结果并不好。