这篇文章发表在
CVPR2014上面,是第一篇展示CNN可以在PASCAL VOC数据集上带来明显更好的目标检测性能的文章。提出了一种使用selective search+CNN的两阶段的目标检测方法。创新点在于使用CNN提取特征,在大数据集下有监督的预训练,小数据集上微调解决样本数量少难以训练的问题。
Introduction
使用CNN做目标检测需要解决两个问题:一是使用深度网络定位目标;二是使用少量标记数据训练一个高性能的模型。与图像分类不同,目标检测是要在一幅图像中检测出目标,可能有多个。一种方法是将其作为回归问题,比如构建一个滑动窗检测器。
本文提出的R-CNN的整体框架如图,也因为将region和CNN feature组合,所以作者定义为R-CNN(region with CNN features)。
- 输入一幅图像,产生约
2000个类别独立的region proposal - 然后使用仿射图像扭曲(
affine image warping)将每一个region proposal转换为固定尺寸的CNN输入 - 再使用
CNN从每一个proposal中提取固定长度的特征向量 - 对每一个类别训练一个
SVM,然后使用这些特定类别的线性SVM对每一个区域进行分类。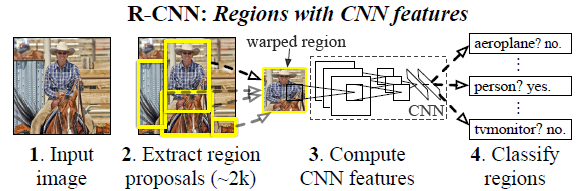
传统的方法解决数据稀缺问题时,使用无监督的预训练和有监督的微调。这篇文章第二个贡献就是当数据稀缺时,在更大辅助数据集(ILSVRC)上使用监督式预训练,然后在小的数据集(PASCAL)上进行特定域的微调,是一种学习高性能的CNN的有效范例。简而言之,就是使用图像分类中的经典网络作为基础网络,然后在目标检测这种任务上,进行微调。
Object detection with R-CNN
分为3个模块:
- 第一个模块生成类别独立的
region proposals,使用selective search生成。就是采取过分割手段,将图像分割成小区域,再通过颜色直方图,梯度直方图相近等规则进行合并,最后生成约2000个候选框 - 第二个模块是一个大的卷积神经网络,从每一个区域中提取固定长度的特征向量。通过前向传播
227x227的图像(减均值),经过5个卷积层和2个全连接层,对每一个region proposal计算得到4096的特征向量 - 第三个模块是一系列的特定类别的线性
SVM。
Test
- 选择性搜索提取候选区域框,每个候选框周围加上
16个像素值为候选框像素平均值的边框,再直接缩放到网络输入227x227 - 每一个候选框输入到
CNN之前,先减去均值,经AlexNet网络提取4096维的特征,2000个候选框就组成2000x4096的矩阵 - 将
2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘,获得每个候选框对应类别的得分,Pascal VOC数据集有20类目标 - 每一类都有多个候选框,因此要进行非极大值抑制,去掉重叠候选框
- 用
20个线性回归器对得到的每个类别的候选框进行回归,获取目标位置
Training
- 监督式预训练,在
ImageNet数据集上进行,使用图像分类的数据,只有类别标签,没有bounding box。 - 特定域的微调
- 只使用来源于
VOC的数据做随机梯度下降,以训练CNN参数,初始学习率设为0.001,每一次SGD迭代(这里指的就是mini-batch梯度下降),在所有类别中均匀采样32个正样本,和96个背景区域,组成一个128的mini-batch - 用
21way的分类层替代原来的1000way分类层。 - 根据
bounding box的所属的类别,把那些与ground truth的IoU大于0.5的region proposal作为正样本,其余的作为负样本。
- 只使用来源于
- 目标分类器
- 一个图像区域紧紧包围住一辆车,则这个区域就是正样本。所以正样本就是
bounding box的ground truth。文中选择0.3作为IoU阈值,低于这个阈值的区域作为负样本。 - 提取好样本的特征,就可以优化每一个类别的
SVM。由于训练数据太多,采用标准的难负样本挖掘方法(hard negative mining),可以使训练快速收敛。
- 一个图像区域紧紧包围住一辆车,则这个区域就是正样本。所以正样本就是
这里也可以看出,在微调CNN和训练SVM时,对于正负样本IoU阈值的限定不一样,前者的限定更加宽松,这是因为CNN需要大量的样本,否则会过拟合,而SVM就可以使用相对少量的样本,故限制更严格。
Detail
bounding box回归:选择性搜索产生的region proposal输入到CNN中,文章中CNN使用的是AlexNet,将AlexNet的Pool5产生的特征用来训练线性回归模型,从而预测bounding box的位置。在回归中,如果候选框与ground truth距离太远,训练是很困难的几乎没有希望,所以在样本对的选择上,只选择那些与ground truth离得近的,文中通过设置proposal和IoU阈值为0.6,低于阈值的proposal就没有匹配的ground truth,被忽略掉。- 目标类别:使用倒数第二个全连接层
fc7输出的特征,训练分类器SVM或者softmax - 两者的结合:一个
region proposal送入卷积神经网络,Pool5和倒数第二个全连接层fc7的特征会先保存下来;然后使用所有类别的SVM对这个proposal预测类别分数,决定是否为某种目标;如果是某种目标,则用相应类别的线性回归去预测得到bounding box的位置。
问题
- 处理速度慢,主要是因为一张图片产生的约
2k个候选框由CNN提取特征时,有很多区域的重复计算 - 整个测试过程也比较繁琐,要经过两阶段,而且单独进行分类和回归,这些不连续的过程在训练和测试中必然会涉及到特征的存储,因为会浪费磁盘空间。